【CRIWARE】BEATWIZ功能解说故事 第三话:听我的歌声
之前有提到,将输入的乐曲根据“符合作曲家意图的MBT单位”进行重新解析,从而获得了在这之前没办法通过直观感受来获取的定量的信息。
这次,我们会关于技术的进一步发展,
把“带有人声的曲子”的“人声”的部分和“其他的部分”进行“主唱分离”的话题,
以及使用分离的“主唱成分”来生成“主旋律的乐谱”的话题。
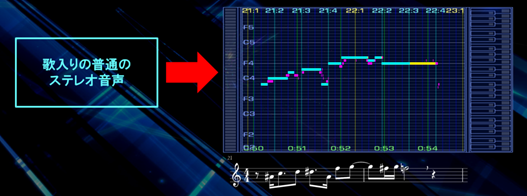
?从带有人声的乐曲,几乎实时的将主旋律的乐谱调取出来的DEMO。
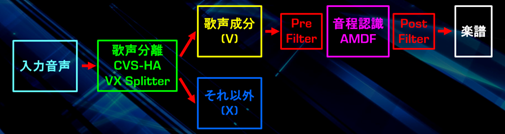
首先将主唱分离之后进行音程解析之后生成乐谱。
听我的歌声
现在新冠流行,虽然可能减少了,在大城市里一定会有人声,车声,电车声等各种大量的杂音。
大家在城市的嘈杂声中,是不是会有下面的经历?
1. 在嘈杂的环境中,呼叫自己的声音能够切实的听见
2. 在噪音中,人声的人声部分能够单独的听出来
3. 在车内,打电话的声音非常的令人烦躁
像这样,“人的声音”非常的特别,不能简单的作为一种声音来考虑。
因此我假定存在一种和“人的声音”一样,对于人的耳朵来说更容易和“周围”的声音区别开来的这么一种声音,通过将这个概念量化,是不是就可以进行“主唱分离(抽出)”。
这里不讲解得过于详细,“人的声音”有一种叫做“调和性”的东西,为了计算这个“调和性”,用了叫做CVS-HA(Complex Vector Space Harmonic Analysis)(复杂向量空间震动解析)的方法。这个是着眼于在高速傅里叶变换的输出结果的,从前不太重视的“位相成分(phase)”的手法。
通过这个方法,可以比较好的从带有人声的立体声音乐里,提取“人声(V)”和“除人声以外的声音(X)”。
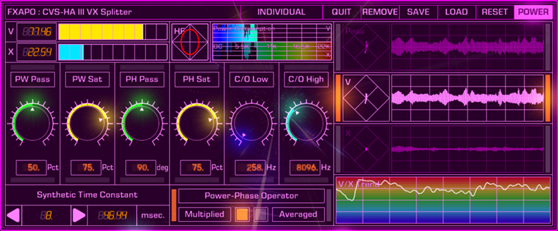
在BEATWIZ里,这个把“人声(V)”和“除人声以外的声音(X)”分离的系统,也就是“主唱分离滤波器”,我们叫做“VX Splitter”,上图就是执行画面。

VX Splitter可以实时的分离带有人声的乐曲的”人声(V)“和”“除人声以外的声音(X)”。
上图是一首叫做“Pass”的带有人声的立体声歌曲的源波形,“V”就是分离出来的人声,“X”则是除此之外的其他声音。
一般的带有人声的立体声歌曲,人声部分定位在中央的情况比较多,要消去人声部分需要从左声道到右声道进行除算,也就是所谓的“L-R法”。
用这个方法可以“消去人声”,但是不能“保留人声”。
并且“剩下的成分”会变成单声道信号。
但是使用VX Splitter的话,可以单独获取“人声(V)”成分,并且V和X两边都是立体声信号。

然后,VX Splitter可以实时的对“人声(V)”占全体声音的比率进行计算。
上图是VX Splitter在某一个瞬间的执行状态,在这个瞬间“人声(V)”占全体声音的比率为77.46%。
分析音高的方法(AMDF法)
在前面一章我们说明了关于可以使用VX Splitter来分离“人声”。
要计算分离出来的“人声”的音高,则需要使用和“高速傅里叶变换(FFT)”完全不一样原理的“AMDF方法(Average Magnitude Difference Function)”
在这之前,我们先来考虑一下人声的声域到底是个什么范围。
一般人在说话的时候,男声在120~200Hz,女声则在200~300Hz的范围。
而在唱歌的时候,一般人的音域在2个八度音阶,可以参考下表。
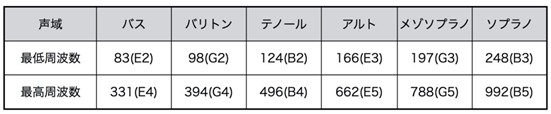
(括号里指的是音阶名称(国际式))
所以一般人的情况下,只需要测定80Hz~1000Hz,专业的歌手的话,也可以发出80Hz以下或者1000Hz以上的声音。
熟练掌握假声的话,还可以用更高的频率唱歌。
所以最终,人声的测定范围我们使用了65Hz(C2)~4kHz(B7)。
在这里,简单说明一下测定音高所使用的AMDF方法。
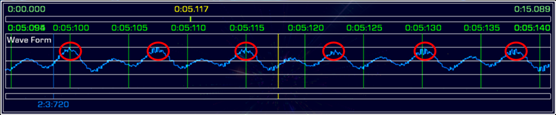
这是我发出“yi”声的时候的波形,用红色的圈圈住的比较有特征的波形大概每7.5ms出现一次。
这个7.5ms换算成频率1秒/0.0075秒=133.33Hz。
这个就是“基本频率”。
133.33Hz'和C3(131.41Hz)比较接近,因此可以判定这个声音的音高为C3(do)。
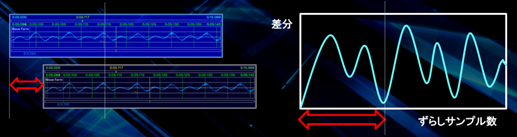
这个“基本频率”通过AMDF方法来推导的方法大概就是以下的步骤。
1. 将同一个波形堆积到2个缓冲器(Buffer)里。
2. 将其中一个缓冲器里的波形向后每移动一个样本数(Sample),然后计算一次和原本波形的差分。
3. 当波形移动了一个周期之后,波形会和原本的重叠,差分的值将变得最小。
4. 错开的波形的样本数量为一个周期的长度,因此使用样本频率(44.1kHz = 44100Hz)来计算周期的时间(长度),在这个例子里,红色的箭头的长度为331个样本数,331/44100 = 0.0075056秒。
5. 周期的倒数就是基本频率。(1/0.0075056=133.233Hz)
当然仅仅这样计算,很多时候都不能准确的计算音高,像下图这样,在计算的前后还会导入比较强的滤波器。(滤波器的详细就不再赘述)
像这样,通过分离“带有人声的乐曲”的“人声”,然后最终得出了乐曲的主旋律。
将这个和乐谱绘图工具向结合之后,就做到了“仅仅输入一首带有人声的乐曲”,就能如下图所示实时的输出主旋律的乐谱了。
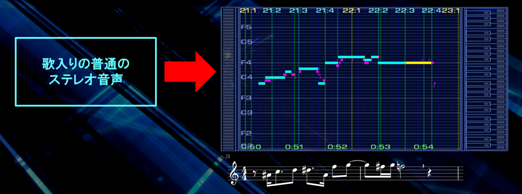
这个通过带有人声的歌曲来输出主旋律部分的乐谱的工具,就是BEATWIZ里实装的“乐谱绘制引擎”,我们称之为”eMUTE(Emotional MUsic Transcription Engine)“
下回预告
现在我们的BEATWIZ终于可以输出“歌曲的主旋律的乐谱”了。
不过经过不断的研究,发现还是有很多乐曲没办法很好的进行解析。
所以在最后的第4话里,我会对关于
在CEDEC2020演讲过的“使用了Constant-Q变换的和音解析”,以及利用了Constant-Q变换的更高精度的“乐句解析”以及“主旋律乐谱的输出”,进行解说。
请大家期待。
关于eMUTE(乐谱绘制引擎)的滤波器,以及基于AMDF方法的音高识别技术的详细,
可以参考CEDiL(CEDEC Digital Library)