由浅到浅入门批量渲染(完)
好久不见。
这是第36篇与游戏开发有关的文章。
上回简述了与优化骨骼蒙皮动画有关的内容,接下来我们将来到《由浅到浅》系列的最后一篇:介绍两种批量渲染骨骼蒙皮动画单位的优化方案:烘焙顶点动画和烘焙骨骼矩阵动画。
简单来说,它们基本的思路,都是将骨骼蒙皮动画的“结果”预先保存在一张纹理中;然后在运行时通过GPU从这张纹理中采样,并使用采样结果来更新顶点属性;再结合实例化技术(GPU instancing),达到高效、大批量渲染的目的。
如果你之前对这类优化方案并不了解,看了上面的描述,也仍然一头雾水;那太好了,这篇文章(没准)可以帮助你快速入门这类优化方案。
下面我们就简单的介绍一下它的工作流程及原理吧。
| 烘焙顶点动画
可以简单的将它的工作流程分为两个阶段:
- 非运行状态下的烘焙阶段
- 运行状态下的播放阶段。
烘焙阶段
这个阶段其实是为后面的播放阶段准备动画资源,你也可以把这个资源简单的理解为一种特殊类型的动画文件。
首先,在编辑状态下,让携带骨骼蒙皮动画的角色,按照一定帧率播放动画。
非运行状态下播放动画
我们知道:动画播放时,角色网格会被蒙皮网格渲染器(SkinnedMeshRenderer)更新而产生变形(顶点变化);如果在动画播放的同时,记录下每一个顶点在这一时刻相对于角色坐标系(通常是角色脚下)的位置。那么,当动画播放完毕时,我们会得到一张“每一个顶点在每一个关键帧时的位置表”,我们就叫它“帧顶点位置表”吧。
可是“帧顶点位置表”名字太长,你可能不太好记,我打字也比较麻烦,所以我们后面就叫它“表表”吧。
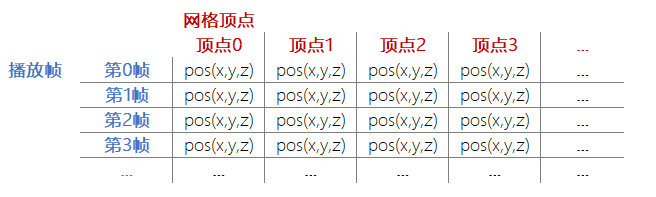
播放某动画时,记录下的表表
除了表表,我们还能得到与它对应的动画信息,比如这个动画的名称、时长、帧率、总帧数、是否需要循环播放等信息。
到这里,第一个阶段我们需要的内容就准备就绪了,可以进入下一个阶段:播放动画阶段。
播放阶段
在动画播放时,通过一个变量(播放时长)来更新播放进度;结合上一阶段我们记录下来的动画总长度、动画总帧数信息,就可以计算出当前动画播放到了第几帧(当前帧数 = 已播放时长 / 动画总时长 x 动画总帧数)。
一旦得到当前动画帧,就表示可以通过表表锁定一行顶点数据。
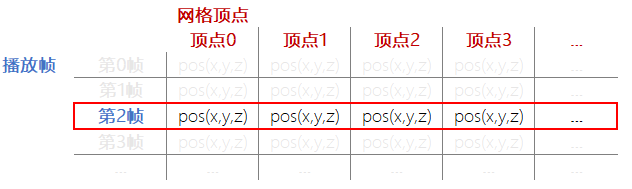
通过关键帧找到的顶点数据
接下来,只要遍历这行顶点数据;然后根据索引找到网格中对应的顶点并更新它的位置,就等于完成了蒙皮工作。
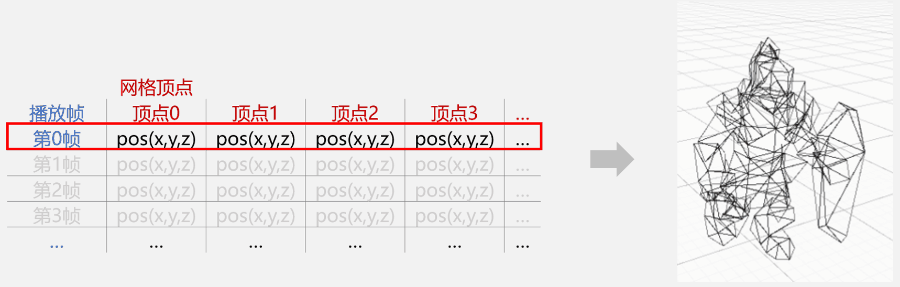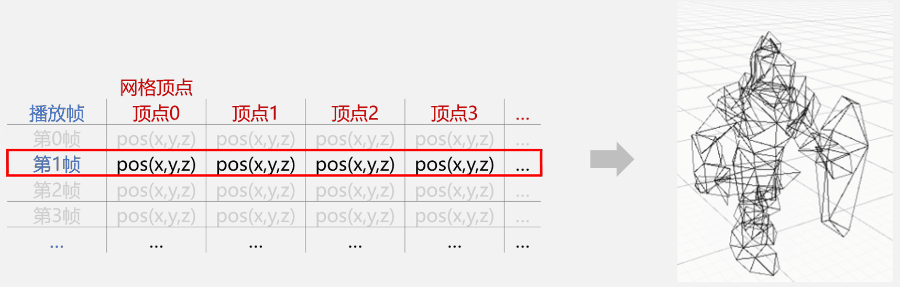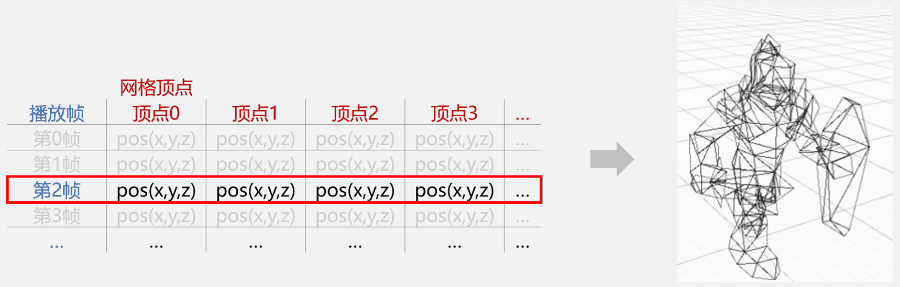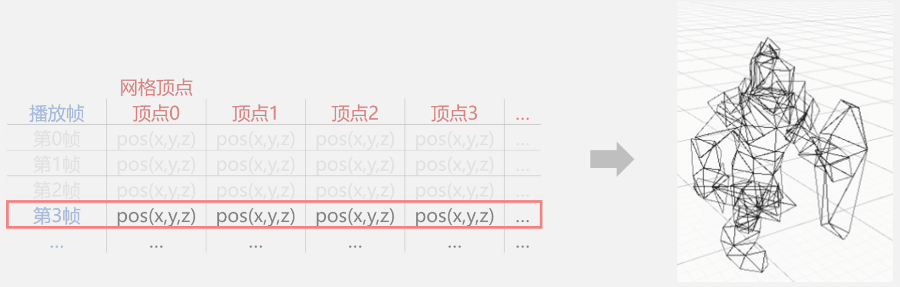
每一帧都通过表表来更新顶点属性,动画就播放起来了
如你所见,使用这种方式来更新角色动画,其实是直接使用了预先处理好的骨骼动画、蒙皮网格渲染器的作用结果,是一种用空间换时间的策略。
既然通过一个播放进度、表表和一些简单的动画信息,就能直接完成蒙皮(对顶点属性的更新),那么我们就不再需要以下内容了:
- 骨骼信息
- 动画控制器
- 蒙皮网格渲染器
使用CPU来读取表表,并遍历更新所有顶点,显然不如GPU来的高效;所以接下来,我们将这一步放到渲染管线中的顶点变换阶段,借着GPU处理顶点的契机,完成使用表表中的数据对顶点属性进行更新。
| 使用纹理保存动画数据
首先,为了便于GPU读取表表,我们将其保存为一张纹理,可以称之为动画纹理。
比如,对于一个拥有505个顶点的模型来说,我们可以将表表中的信息保存到一张 512 x Height 大小的纹理中。
这其中,纹理的宽度用来表示顶点的数量,而纹理的高度用来表示关键帧,所以Height的值取决于动画长度以及动画帧率。
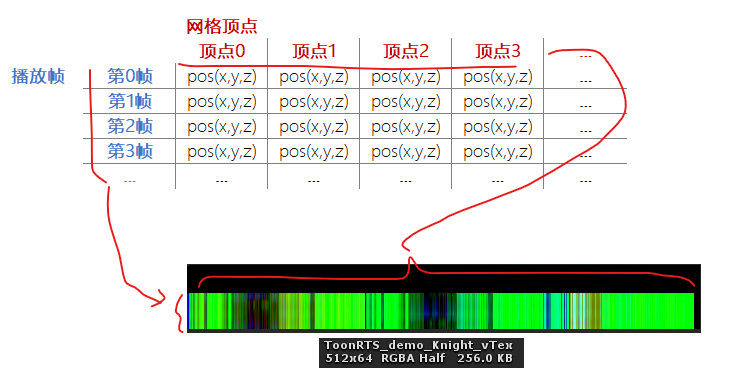
将表表中的顶点位置“烘焙”到纹理中
我们通过UV坐标来获取这张纹理上的像素,就可以被理解为:取第U个顶点在第V帧时的坐标。
当然,除此之外,我们还会将动画信息保存成为动画资源,将重要信息进行序列化(动画名称、动画长度、总帧数、是否循环等)。
使用ScriptableObject保存动画信息
后面的事情就简单了:在播放动画时,CPU将当前播放的关键帧传给顶点着色器;顶点着色器计算出对应的V坐标;结合顶点索引及动画纹理的宽度计算出U,既可采样出这个顶点基于角色坐标系下的坐标;接下来用这个坐标再进行后面的空间变换就可以了。
法向量
由于动画播放时,顶点的实时位置是从纹理中采样,而非从网格中读取的(不再使用蒙皮网格渲染器,顶点缓冲区内的数据不会被修改),所以顶点属性中的法线信息也无法使用了(永远是静止状态下的);如果需要获取正确的法向量,那就需要在烘焙顶点坐标时也同样将法线烘焙下来,并在顶点变换阶段将这个法向量也采样出来。

烘焙的法线纹理
存在多个动画
通常情况下,角色不会只包含一个动画;比如小兵通常拥有空闲、移动、攻击三个动画。如果对每一个动画都烘焙一或两张(法向量)纹理,那贴图的数量将很快不受控制。鉴于所有动画对应的顶点数量一致,也就是纹理的宽度都相同,我们可以将多个动画纹理进行合并。

三个动作被合并到了一张纹理中
将多张动画纹理进行上下排列、合并后,我们只要将每个动画的起始、终止的V坐标范围追加到动画资源中即可。然后在播放、切换动画时,根据当前动画所在的起始位置以及播放进度,就能算出正确的V坐标了。
保存动作信息时需要额外记录一些属性
当然,如果网格的顶点数量少,而动画数量多,我们也可以多列放置动画(前提是放的下)。

多列放置动作
动画过渡
简单的动画过渡很容易实现,只要在切换动画时,分别计算出当前动画和下一个动画的播放位置,然后传给GPU进行两次顶点位置采样,再对两次采样的结果进行插值即可。

带动画过渡

不带动画过渡
使用实例化渲染
实例化渲染的特点是使用相同网格,相同材质,通过不同的实例属性完成大批量的带有一定差异性的渲染;而烘焙顶点恰好符合了实例化渲染的使用需求。
所以,我们只需将控制动画播放的关键属性:比如过渡动画播放的V坐标、当前和下一个动画的插值比例等,放入实例化数据数组中进行传递;再在顶点着色器中,对关键属性获取并使用即可。
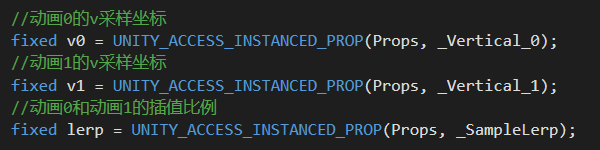
实例化渲染时获取到的关键属性
当然,如果你想实现更多不同的效果,比如你附带了一张遮罩纹理,用来调整diffuse或做某些特殊的计算,那你也需要将控制参数加到实例化数据中就可以了。
顶点着色器采样
在顶点着色器中是无法使用tex2D进行采样的,需要使用tex2Dlod进行代替,但是这个特性需要shader model 3.0(#pragma target 3.0)才可以支持。
顶点索引
可以通过语义SV_VertexID来获取顶点索引,但是在移动平台上这个特性需要OpenGL ES3.0(#pragma target 3.5)才可以使用(当然也可以在烘焙阶段将顶点索引保存到网格属性中)。
与蒙皮网格渲染器的比较
- 不再需要CPU计算动画和蒙皮,提升了性能
- 可以通过实例化技术批量化渲染角色,减少DC
烘焙顶点的主要问题
- 模型顶点数量受限:如果纹理的最大尺寸限制在2048 x 2048,那么只能烘焙下顶点数在2048个以下的模型
- 记录顶点动画的纹理过大:(顶点位置)纹理格式需设置为TextureFormat.RGBAHalf
- 存储的动作长度有限
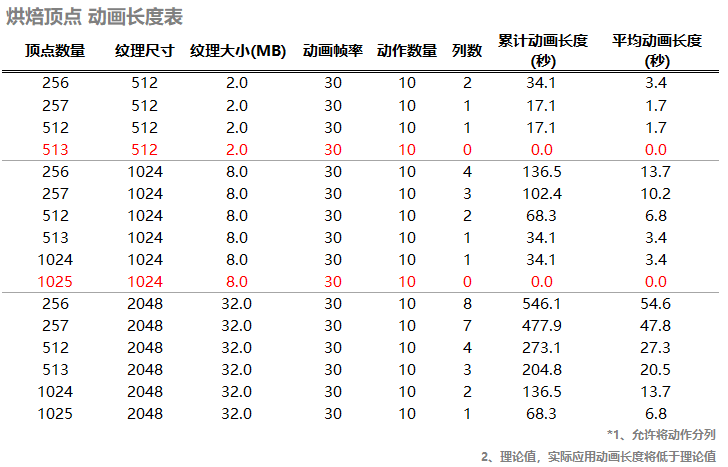
烘焙顶点的动画长度参考表
| 烘焙骨骼矩阵
除了烘焙顶点,另一种常用的优化方案是烘焙骨骼矩阵动画。
听名字就知道,烘焙骨骼矩阵与烘焙顶点位置,原理十分相似;最大的差异在于它们在烘焙时所记录的内容不一样:烘焙顶点记录下来的是每个顶点的位置,而烘焙骨骼矩阵记录下来的是每一根骨骼的矩阵,仅此而已。
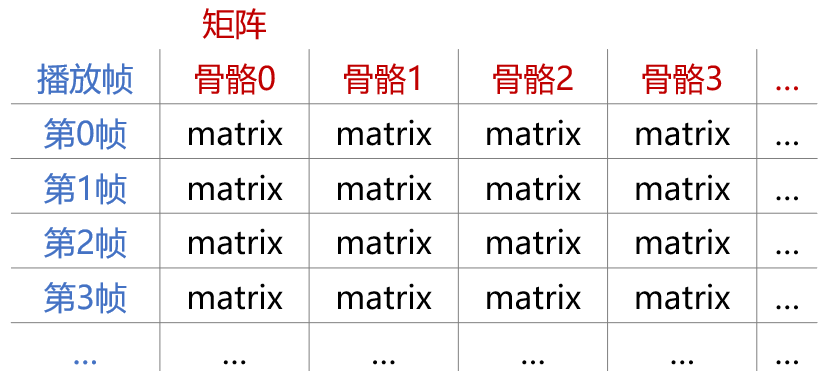
记录下每一根骨骼在每一帧动画播放后的矩阵
烘焙骨骼矩阵最大的意义在于它补上了烘焙顶点的短板:受顶点数量限制、烘焙的动画纹理过大 及 纹理数量较多。
动画纹理使用量差异
烘焙顶点对于纹理(面积)的使用是受顶点数量决定的,可以简单理解为:
纹理面积使用量 = 顶点数量 x 动画长度 x 内容数量
所以,当模型的顶点数量过多时(数以千计),这种烘焙方式或者无法烘焙下整个模型(顶点数量>2048),或者需要一张或多张(法线、切线)大尺寸纹理(<2048 && > 1024)。
但是,烘焙骨骼矩阵主要取决于骨骼的数量,可以简单理解为:
纹理面积使用量 = 骨骼数量 x 动画长度 x 矩阵烘焙方式(x1、x2 或 x3)
在移动平台上,通常20根左右的骨骼就可以取得不错的表现效果,所以相对于烘焙顶点,烘焙骨骼可以记录下更长的动画,同时它也不再受顶点数量的限制,也无需对法线或切线进行特殊处理(因为可以在采样后通过矩阵计算得出)。
两种方式烘焙的动画纹理尺寸差异较大
烘焙阶段
与烘焙顶点相似,烘焙骨骼也需要先在非运行状态下,预先播放一次动画;并在动画播放时,记录下每个关键帧下每根骨骼的转换矩阵。
这里有三点需要注意。
第一,记录下的矩阵是每根骨骼从网格坐标系转换到角色坐标系下的矩阵:
Matrix_meshToRole = Matrix_boneLocalToRole x Matrix_meshToBoneLocal
Matrix_meshToBoneLocal可以通过mesh的bindposes获取;而Matrix_boneLocalToRole可以通过bone的transform计算获得。
第二,需要将每个顶点与骨骼的关系记录到网格信息中,这个关系是指顶点会被哪根骨骼影响(骨骼索引)以及影响的大小(权重值)。
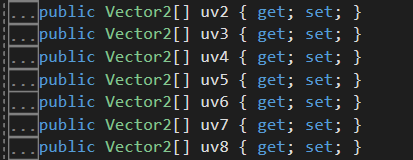
每个顶点最多可以受4根骨骼影响,但是被越多骨骼影响意味着播放时会有越多的采样和矩阵计算,通常限制在2根骨骼就能得到不错的效果;骨骼索引和权重可以通过mesh的boneWeights得知,在烘焙纹理时可以将它保存在mesh中不用的uv中,以便在顶点着色器中获取。
每个uv可以保存下一根骨骼的索引和权重,通常使用两个uv就可以了
第三,对于不同的骨骼动画,烘焙矩阵的方式也不一定相同。
例如,如果骨骼动画中每根骨骼只会相对于上层骨骼进行旋转变换,那我们烘焙一个四元数就够了,也就是一根骨骼的一个矩阵只占用一个像素;但是如果骨骼除了旋转,还有平移甚至缩放的操作,那我们就需要2-3个像素来储存一个骨骼的矩阵了。

拥有特长的角色,需要特殊处理(来自《匹诺曹》)
也可以简粗的将一个矩阵完整的保存在三个像素中
播放阶段
与烘焙顶点相同的是,烘焙骨骼矩阵也是在顶点变换阶段,通过对动画纹理的采样,完成顶点坐标计算的;但是它的计算方式相对于烘焙顶点要复杂一些。
这里主要是需要根据烘焙矩阵的方式,通过采样来还原从网格坐标系到角色坐标系的转换矩阵;例如,在烘焙阶段将完整的矩阵保存在三个像素中,那转换时就需要采样三次才能拼凑出一个完整的矩阵。
当然,一旦得到转换矩阵,角色坐标系下的顶点位置、法向量等就可以通过计算获取,后面的变换就可以继续了。
相比于烘焙顶点
正如前文所说,烘焙骨骼不再受顶点数量的限制,可以记录下更长的动画时间,烘焙纹理的尺寸和数量也有明显的优势。
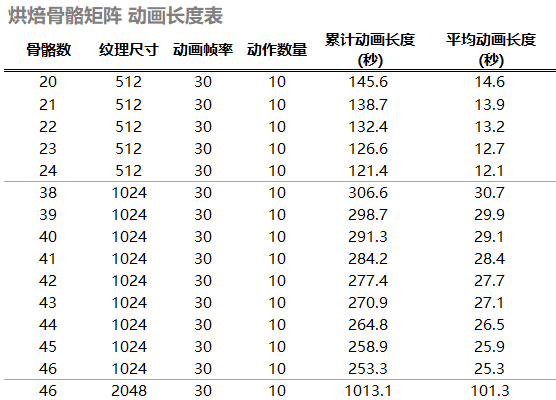
烘焙骨骼的动画长度参考表
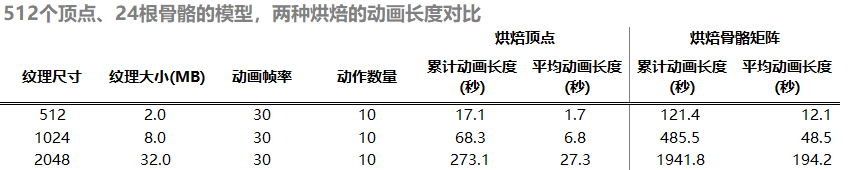
相同模型下的烘焙动画长度对比
但是,烘焙骨骼这种方式会在顶点着色器中需要进行多次顶点采样,在模型顶点数较多、或渲染单位数量较多时,其效率会略低于烘焙顶点。

烘焙骨骼的在顶点着色器中的采样更多

两种烘焙方式分组比较
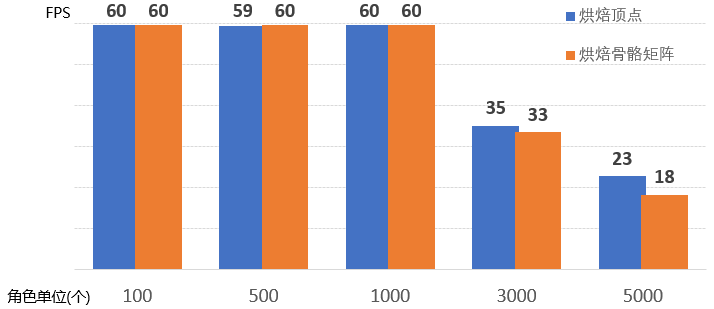
华为P20上的两种烘焙方式的对比
| 小结
以上,就是针对批量渲染骨骼蒙皮动画单位的两种优化方案。
针对这两种方案,我个人认为并没有绝对的孰优孰劣;正如你所看到的,烘焙骨骼在处理复杂模型或多动作时更具优势;但如果渲染数量较多、模型顶点数较少、表现需求较弱(无需法向量参与计算)时,烘焙顶点也是值得尝试的,因为它在性能上会更好一些。
其他优化方案
其实,除了上述两种优化方案外,坊间还有一些特殊的小技巧:比如在手游《三国志大战M》的开场战斗表演中,某些带动画的模型角色,也通过实例化达到了批量渲染的目的。
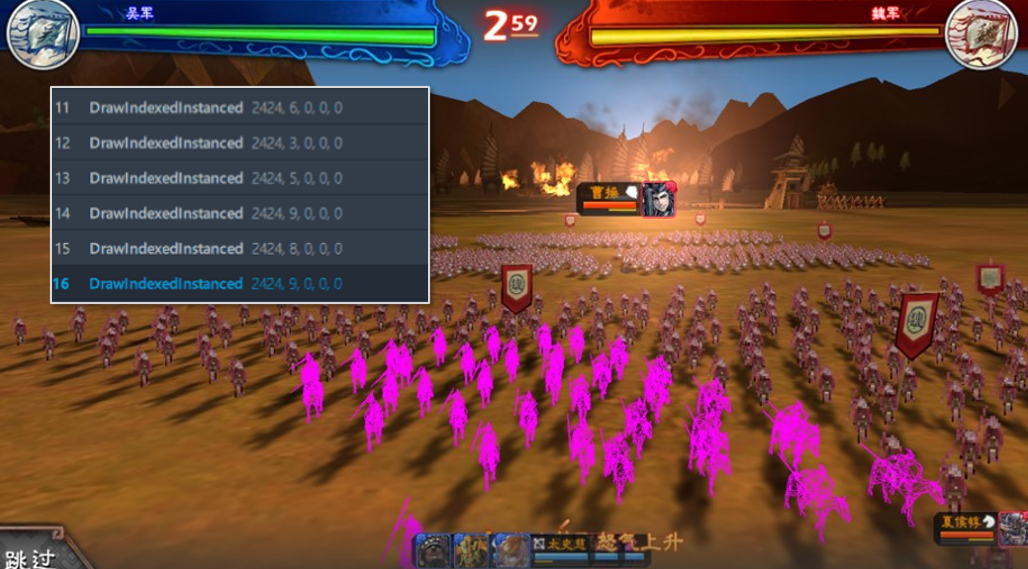
部分小兵不是简单的“片”,而是带模型的单位
但是通过GPA抓帧工具,会发现同一个模型的网格会在同一帧存在多个不同的“姿势”;我推测这里应该是将利用了若干个、使用相同模型的、骨骼蒙皮动画的播放“结果”,通过实例化渲染的方式,复制到多个位置上,由于每个骨骼蒙皮动画的播放进度都略有不同,它们混在一起后的效果就会比较自然,不失为一种巧妙的方法。
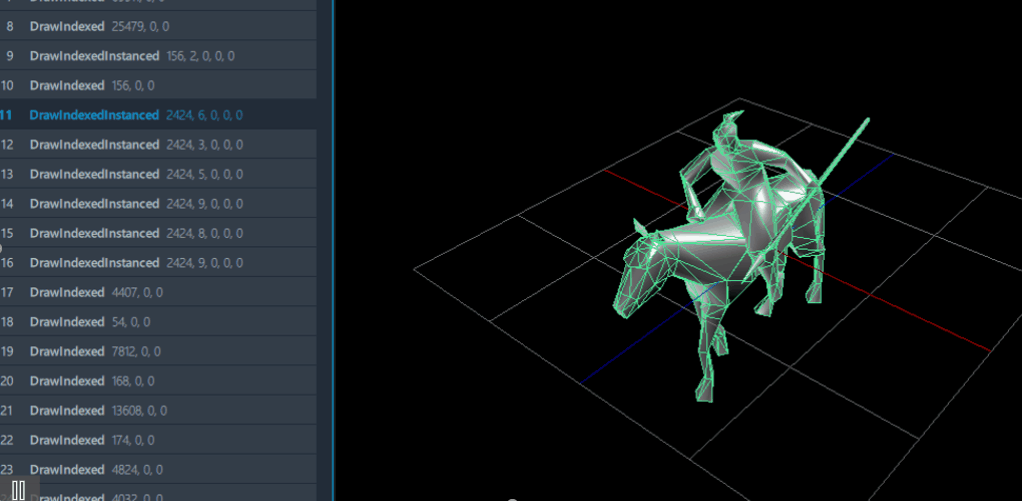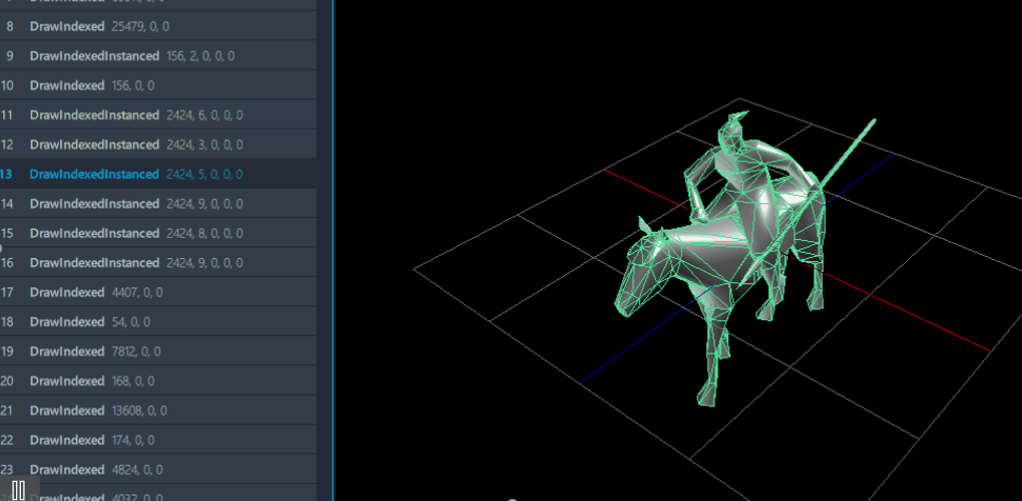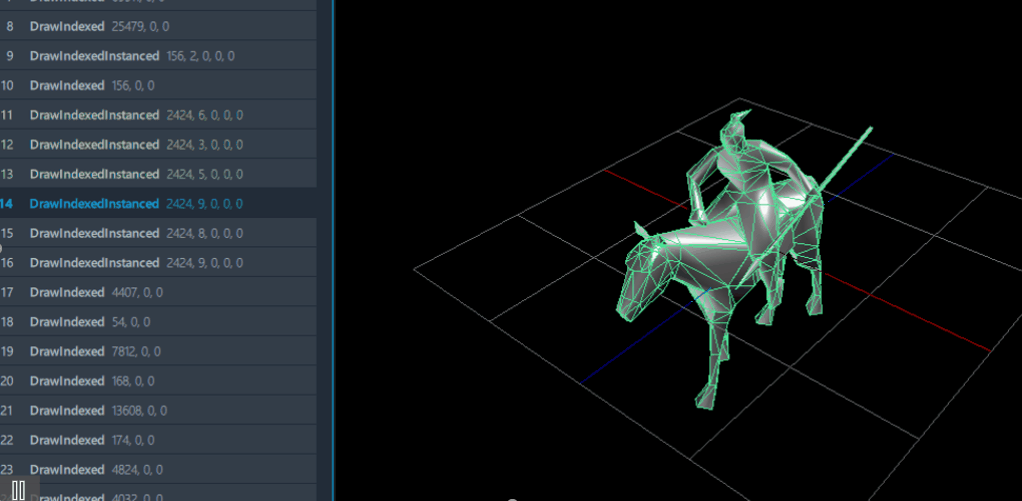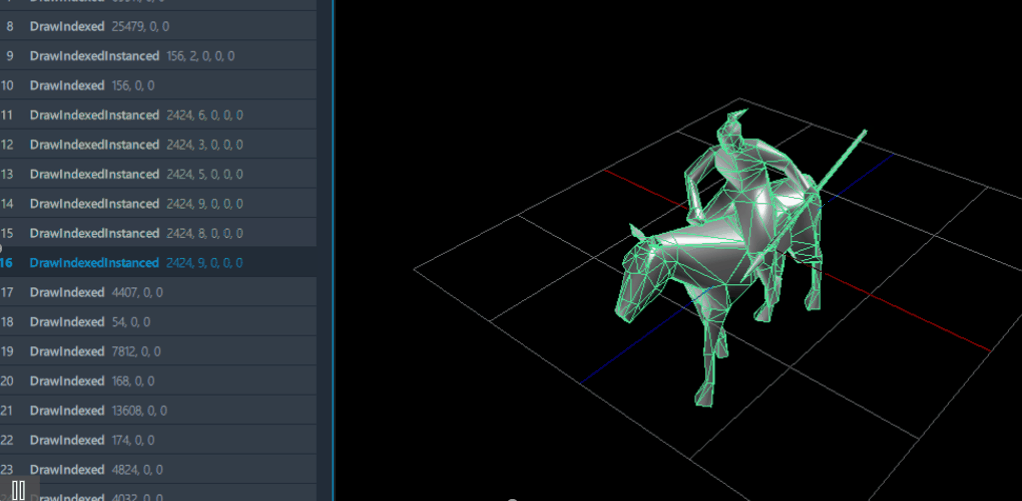
渲染时每个模型的“姿势”都略有差异
| 写在最后
至此,这回的《由浅到浅入门批量渲染》系列就全部更新完了。
快到年底了,是时候总结一下碌碌无为的2020年,并为迎接2021年做些准备了,所以今年就不计划再更新文章了。
明年见。
我的公众号 偶尔学学Unity 会特别不定期更新与游戏开发可能有关的文章,欢迎关注,谢谢。
