由浅到浅入门批量渲染(二)
好久不见。
这是第33篇与游戏开发有关的文章。
上回简单总结了一下静态合批,这次我们继续说说动态合批。
| 动态合批
试想一个场景:一场激烈的战斗中,双方射出的箭矢飞行在空中,数量很多,材质也相同;但因为都在运动状态,所以无法进行静态合批;倘若一个一个的绘制这些箭矢,则会产生非常多次绘制命令的调用。
让人热血沸腾的一场激战
对于这些模型简单、材质相同、但处在运动状态下的物体,有没有适合的批处理策略呢?有吧,动态合批就是为了解决这样的问题。
动态合批没有像静态合批打包时的预处理阶段,它只会在程序运行时发生。动态合批会在每次绘制前,先将可以合批的对象整理在一起(Unity中由引擎自动完成),然后将这些单位的网格信息进行“合并”,接着仅向GPU发送一次绘制命令,就可以完成它们整体的绘制。
动态合批比较简单,但有两点仍然需要注意:
1、合批并非是在绘制前“合并网格“
动态合批不会在绘制前创建新的网格,它只是将可以参与合批单位的顶点属性,连续填充到一块顶点和索引缓冲区中,让GPU认为它们是一个整体。
在Unity中,引擎已自动为每种可以动态合批的渲染器分配了其类型公用的顶点和索引缓冲区,所以动态合批不会频繁的创建顶点和索引缓冲区。
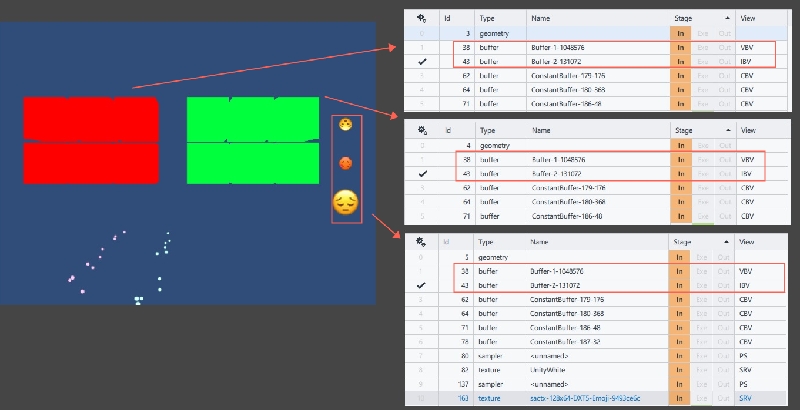
MeshRenderer、SpriteRenderer动态合批时使用了公用的顶点、索引缓冲区
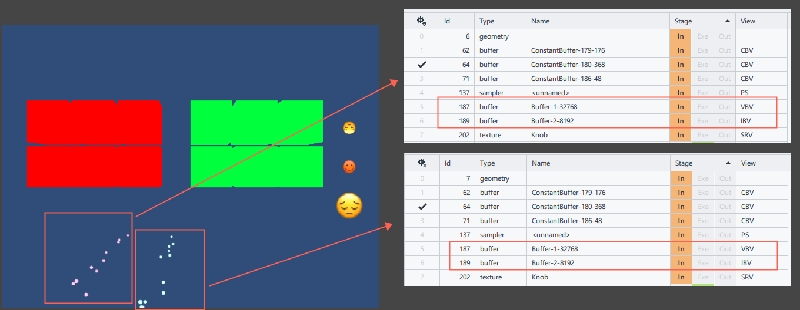
ParticleSystemRenderer动态合批时使用了与MeshRenderer不同的公用顶点、索引缓冲区
2、合批前会先处理每个顶点的顶点属性
在向顶点和索引缓冲区内填充数据前,引擎会处理被合批网格的每个顶点信息,将其空间变换到世界坐标系下。
这是因为这些对象可能都不属于相同的父节点,因此无法对其进行统一的空间转换(本地到世界),需要在送进渲染管线前将每个顶点的坐标转换为世界坐标系下的坐标(所以Unity中,合并后对象的顶点着色器内被传入的M矩阵,都是单位矩阵)。
Unity动态合批的条件
相对于上述看起来有点厉害但是本质上无用的知识而言,了解动态合批规则其实更为重要。比如:
- 材质球相同;
- Mesh顶点数量不能超过300以及顶点属性不能超过900;
- 缩放不能为负值(x、y、z向量的乘积不能为负)等。
但我个人认为你不需要记住每一个条件,除了上述相对重要些的条件外,其余的可以通过FrameDebugger中提示的合批失败原因,来反向了解合批条件。
与静态合批的差别
动态合批与静态合批最大的差别在于:
1、动态合批不会创建常驻内存的“合并后网格”,也就是说它不会在运行时造成内存的显著增长,也不会影响打包时的包体大小;
2、动态合批在绘制前会先将顶点转换到世界坐标系下,然后再填充进顶点、索引缓冲区;静态合批后子网格不接受任何变换操作,仅手动合批后的Root节点可被操作,因此静态合批的顶点、索引缓冲区中的信息不会被修改(Root的变换信息则会通过Constant Buffer传入);
3、因为2的原因,动态合批的主要开销在于遍历顶点进行空间变换时的对CPU性能的开销;静态合批没有这个操作,所以也没有这个开销;
4、动态合批使用根据渲染器类型分配的公共缓冲区,而静态合批使用自己专用的缓冲区。
虽然在Unity中,存在多种可以被动态合批的渲染器类型,而且其合批规则可能也略有不同;但我个人认为其原理应该是相似的,因此这里就不针对每种渲染器做单独的测试和说明了,后面有必要、有机会、有缘分的话,再仔细了解吧,嘿嘿。
| 写在最后
不出意外的话,下次更新的内容应该是实例化渲染。
下回见。
我的公众号 偶尔学学Unity 会特别不定期更新与游戏开发可能有关的文章,欢迎关注,谢谢。
