扒一扒安卓渲染原理
导语:
在测试流畅度的过程中,必不可免的要与FPS,Jank等指标接触,但为了加深理解,今天来简单扒一扒安卓的渲染原理;
PerfDog使用Jank作为来代表游戏流畅度的指标,详情可以看
APP&游戏需要关注Jank卡顿吗?
一.CPU与GPU结构
现在大部分移动端都会配有CPU(中央处理器)和GPU(图形处理器),有的现在还有一块NPU用于处理智能运算。来简单看一下他们的结构;
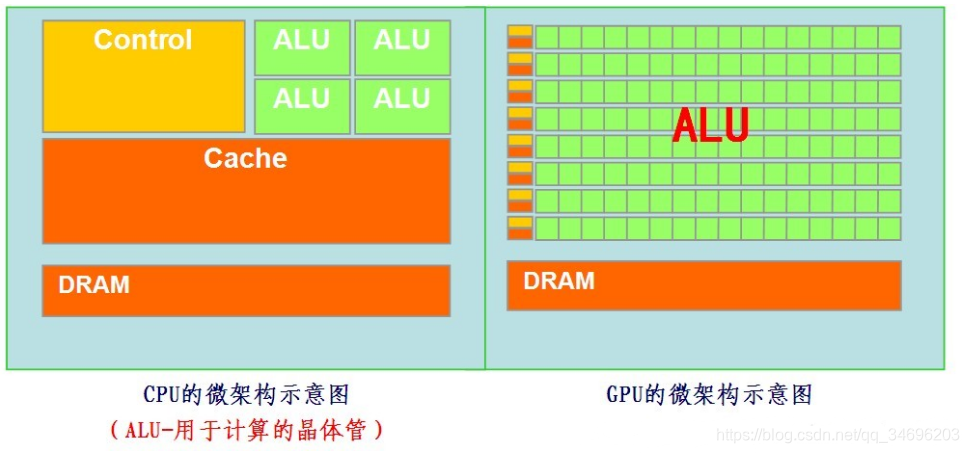
绿色的是计算单元(ALU),
橙红色的是存储单元,
橙黄色的是控制单元。
CPU需要很强的通用性来处理各种不同的数据类型,同时又要进行复杂的数学和逻辑运算,所以使得CPU的内部结构异常复杂;
CPU被Cache占据了大量空间,还有很多复杂的控制逻辑和诸多优化电路,其实计算能力只是CPU很小的一部分,在早期的时候,CPU除了做逻辑计算外,还负责内存管理、图形显示等操作因此在实际运算的时候性能会大打折扣,而且还不能显示复杂的图形,完全不能满足现在3D游戏的要求;所以GPU应运而生。
GPU面对的则是类型高度统一的、相互无依赖的大规模数据和不需要被打断的纯净的计算环境,所以结构也大不相同。
GPU采用了数量众多的计算单元和超长的流水线,但只有非常简单的控制逻辑并省去了Cache,GPU将计算机系统所需要的显示信息进行转换驱动,并向显示器提供行扫描信号,控制显示器的正确显示,主要负责图形显示部分的工作。
二.Android系统绘图机制

现在的安卓终端通常在一个典型显示系统中首先由CPU发出图像绘制指令要让GPU去画一个样式,但CPU不能直接和GPU通信,也要遵守相应的规则,就和现在我们干什么事都要走个流程一样的嘛,不能乱套;所以CPU要先向OpenGL ES发送一些指令,表达要画一个样式,Opengl ES是一组接口API,**通过这些API可以操作驱动,让GPU达到各种各样的操作;GPU接收到这些命令,开始栅格化处理,把样式显示到屏幕中;
现在我们把应用加到显示流程里面来

在Android应用层通过LayoutInflater把布局XML文件映射成对象加载到内存中,此时这个UI对象含有大小,位置啦等等信息。然后CPU从内存中取出这个UI对象,再经过运算处理成多维的矢量图形,然后交给GPU去栅格化成位图,显示到屏幕上;
简单介绍一下矢量图和位图
矢量图:由一个函数来描述,这个函数描述了此图如何生成
位图:由像素点矩阵来描述
Android系统每隔16ms就重新绘制一次Activity,所以要求应用必须在16ms内完成屏幕刷新的全部逻辑操作,这样才能达到每秒60帧(60FPS),然而这个每秒帧数的参数由手机硬件所决定,现在大多数手机屏幕刷新率是60赫兹(是每秒中的周期性变动重复次数的计量),如果超过了16ms就会出现所谓的丢帧(1000ms/60=16.66ms)
三.一帧图像完整渲染过程
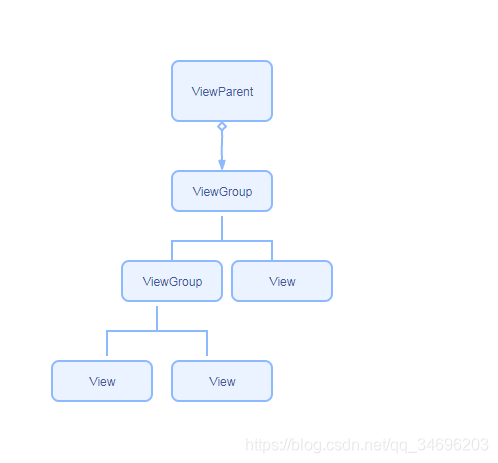
在Android应用程序窗口里面包含了很多视图(View)元素,这些元素是以树形结构来组织,最终构成所谓视图树的结构;
在绘制一个Android应用程序窗口的UI之前,要确定它里面的各个子View元素在父元素里面的大小以及位置。确定各个子View元素在父View元素里面的大小以及位置的过程又称为测量过程和布局过程。Android应用程序窗口的UI渲染过程可以分为
Measure(测量)、Layout(布局)和Draw(绘制)
三个阶段(由ViewRootImpl类的performTraversals()方法发起)
测量——递归(深度优先)确定所有视图的大小(高、宽)
布局——递归(深度优先)确定所有视图的位置
绘制——在画布canvas上绘制应用程序窗口所有的视图
经过多次绘制后,这一帧内要显示的所有view都已经被绘制完毕,注意绘制View层次结构这些操作是在图形缓冲区中绘制完成的;
此时就要把这个图形缓冲区被交给SurfaceFlinger服务
SurfaceFlinger服务概述:
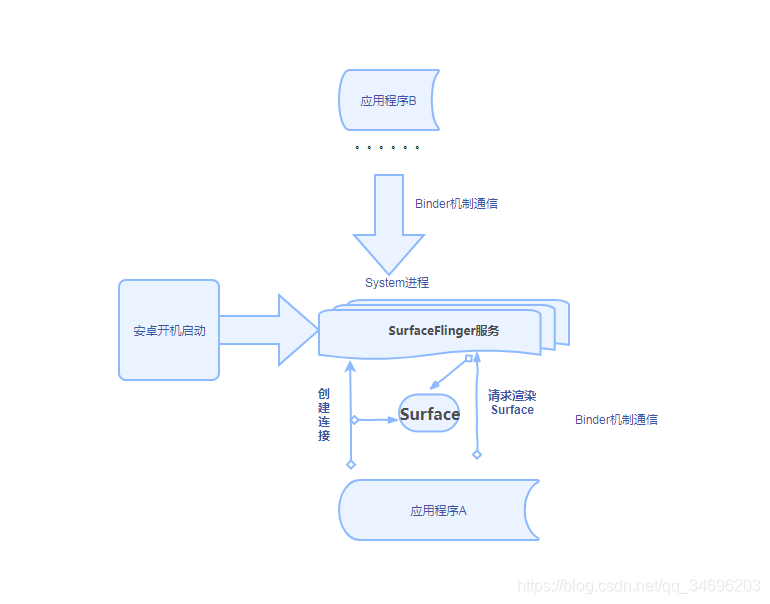
SurfaceFlinger服务和其他系统服务一样是在Android系统的System进程里被启动并运行在其中的,主要负责统一管理设备中Android系统的帧缓冲区(Frame Buffer,简单理解为屏幕所显示出来的所有图形效果都是由它统一管理的),在SurfaceFlinger服务启动的过程中会自动创建两个线程:其中一个线程用于监控控制台事件,另外一个线程则用于渲染系统的UI;
Android应用程序为了能够将自己的UI绘制在系统的帧缓冲区上,就需要将UI数据传递SurfaceFlinger服务并告知自己具体的UI数据(例如要绘制UI的区域、位置等信息),
Android应用程序与SurfaceFlinger服务是运行在不同的进程中,所以相互间通过Binder机制进行通信,
大致可以分为3步:
1.首先是创建一个到SurfaceFlinger服务的连接,
2通过这个连接来创建一个Surface,
3.请求SurfaceFlinger服务渲染该Surface(在Android应用的每个窗口对应一个画布(Canvas),也可以理解为Android应用程序的一个窗口)
在APP层我们对于这部分的无法进行任何的优化,这是ROOM做的工作。
简单来说就是当Android应用层在图形缓冲区中绘制好View层次结构后,应用层通过Binder机制与SurfaceFlinger通信并借助一块匿名共享内存会把这个图形缓冲区会被交给SurfaceFlinger服务。因为单纯的匿名共享内存在传递多个窗口数据时缺乏有效的管理,所以匿名共享内存就被抽象为一个更上流的数据结构SharedClient,在每个SharedClient中,最多有31个SharedBufferStack,每个SharedBufferStack都对应一个Surface即一个窗口。
帧缓存有个地址,是在内存里。我们通过不停的向frame buffer中写入数据, 显示控制器就自动的从frame buffer中取数据并显示出来。全部的图形都共享内存中同一个帧缓存。
四.VSync机制
为了减少卡顿,Android 4.1(JB)中已经开始引入VSync(垂直同步)机制
简单来说就是CPU/GPU会接收vsync信号,Android系统每隔16ms发出Vsync信号,触发对UI 进行渲染(即每16ms显示一帧)
在16ms内需要完成两项任务:将UI 对象转换为一系列多边形和纹理(栅格化)和CPU传递处理数据到GPU。
但即使引入垂直同步机制也不是非常完美,如果某些原因导致CPU和GPU渲染某一帧画面的时间超过16ms时,Vsync垂直同步机制会让硬件显示器等待,直到GPU完成栅格化操作,这就直接导致这一帧画面多停留了16ms甚至更长时间,让用户看起来画面停顿。