口型同步解决方案
一·文章大纲
本文主要通过以下两个方面进行介绍
- 目前游戏口型同步解决方案介绍
- 口型同步解决方案介绍以及应用
通过这两个方面,我们将了解游戏制作过程中口型同步的常规制作方法以及如何通过新的解决方案,高效的在Unreal以及Unity中创建原型与测试效果。
二·正文
一个角色的性格和形象特征主要凸显在三点上:语音,动作以及表情。
对于语音和动作拥有完整的解放方式,通过使用合适的声优以及动作捕捉或动作制作我们能够获得非常好的角色语音和动作特征,但如果没有口型动作,我们在游戏中往往会觉得该角色在剧情表现中缺失了一部分灵魂,也会使得游戏的代入降低不少。
为了解决这一问题,在当前传统的口型同步方案中主要有两种:全系列动作表现,以及跟随语音音量变化。
1·当前游戏口型同步方案介绍
当前口型同步方案有两种,全系列动作表现以及语音音量变化。
(1)·全系列动作表现
所谓全系列动作表现,指的是我们游戏中用到的所有和口型或表情相关的所有内容均由美术制作效果,将其作为一个动作进行输出,当需要使用该表情或口型时,调用相关的动作来达到表现的效果。

这种方式使得角色表情丰富,游戏代入更深。但是也面临一些问题:
·制作量极大,美术需要针对每一句语音制作对应的动作,当语音较多时制作量太大,对于普通厂商来说是一个非常难以解决的问题。
·游戏动作逻辑复杂,因为输出方式以动作进行输出,因此当需要进行表现时就要考虑如何在不同的环境下播放相关的动作,相对来说逻辑较为复杂。
综合来看,虽然直接使用动作进行制作的效果会更加自然但是成本和工作量太大,对于大量语音的游戏不太实用。
(2)·语音音量变化
所谓语音音量变化指使用语音的音量,来控制游戏内口型的张闭,以音量的RMS进行动态的变更,使得模型口型匹配语音。

这种方式非常简单,易于使用,但是分析太过简化,仅仅使用RMS去控制口型形状变化维度太低,没办法实现复杂的口型效果。
·虽然制作量少,但是表现力较差。
这种方式对于精品化游戏没有太大的帮助,因为分析有限所以能够变化口型的维度太低表现力自然较弱。
我们可以看下面的动态效果:

从效果中我们明显看出,如果单纯的使用RMS去控制口部形状变化表现力较差,而且会有非常明显的抖动效果,因为音量的变化是非常迅速的,当口型每帧刷新变形效果也使得口型变动较为鬼畜,影响观赏效果。
那么这两种方式都有各自的优缺点,无论是成本还是效果都不是最佳选择,我们还有其他方法嘛?
这将是本文说明的重心 ADX LipSync口型解决方案。
2·ADX LipSync口型解决方案
ADX LipSync是Criware公司推出的,针对其音频中间件ADX2的口型解决方案。
实际上除了可以和音频中间件ADX2连用外,还能够单独进行使用。
(1)·LipSync说明
LipSync是最新推出的,针对口型匹配的新解决方案。能够实时以及预先分析声音素材,得到声音素材所包含的信息后,将其运用于模型上,通过变更模型的变形效果,综合控制口型的变化,以达到口型和语音匹配的目的。
LipSync主要有两种应用模式,实时解析和预先分析。
- 实时解析可以通过话筒录入实时分析录入的声音内容,进行分析最终得到相关的口型数据,进行模型变形匹配声音口型。
- 预先分析是通过将已经录音处理好的wav文件进行分析,得到相关的分析数据,当播放相关的wav文件时,可以使用事先分析好的数据进行模型的变形以匹配声音口型。
LipSync也拥有两种应用方法,单独使用和与ADX2联合使用
- 单独使用是LipSync单独应用,直接使用LipSync进行声音分析,最终得到口型数据和效果。
- 与ADX2联合使用,这种方式LipSync作为ADX2的插件使用,能够分析ADX2中Cue中Track轨道上的波形文件,生成相应的声音数据。分析相应的数据也可以事先分析或者实时分析,这种应用方式称为ADX LipSync也是本文中介绍的重点内容。
想要使用ADX LipSync口型同步,我们首先需要能够变更口型的模型,下面将通过3D Max简单的介绍如何制作口型数据
(2)·模型口型数据创作
首先我们需要创建好一个包含口型的模型,然后导入到3D Max中:
- 选中模型后按住Shift复制一个副本

- 创建变形器
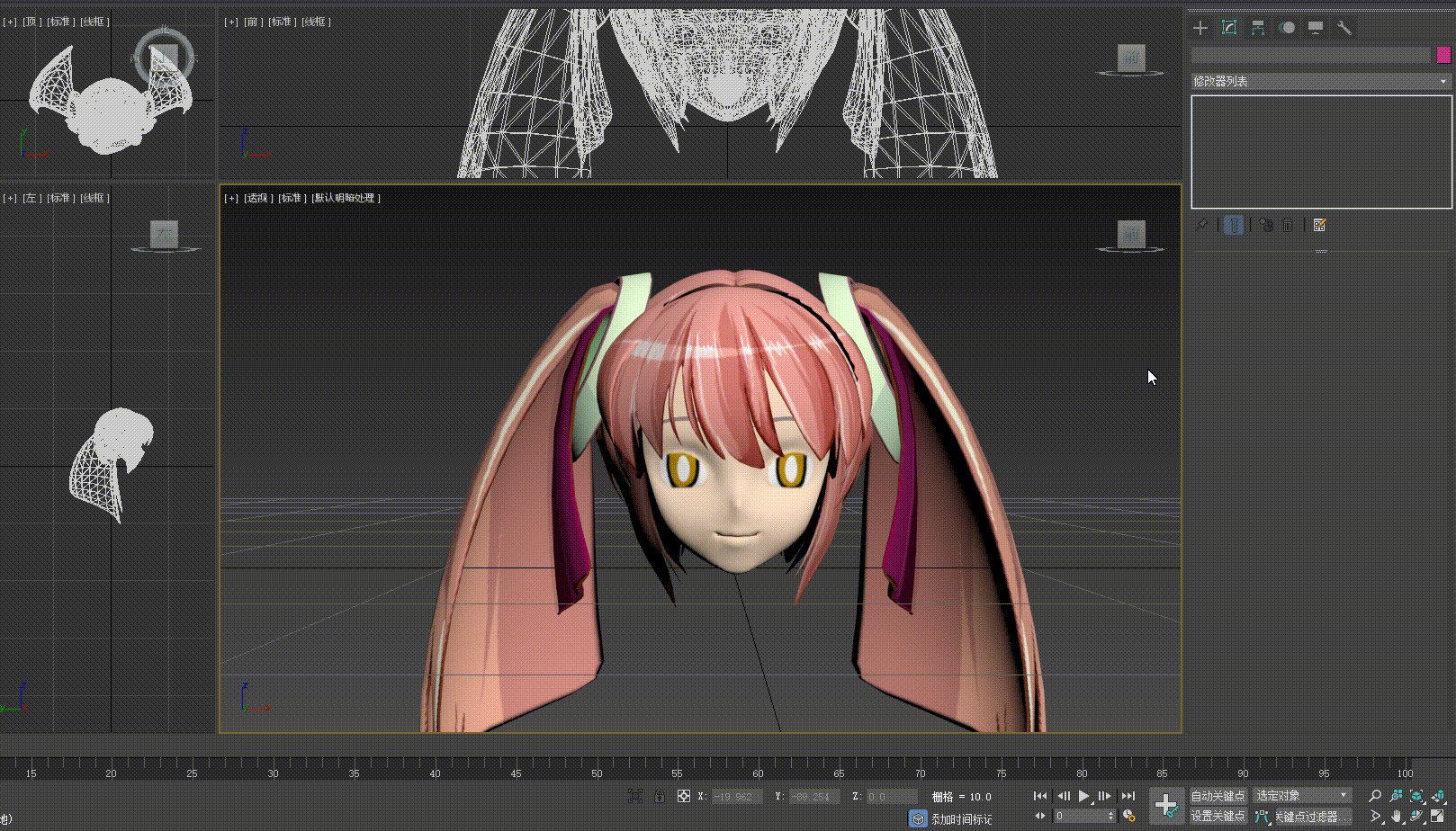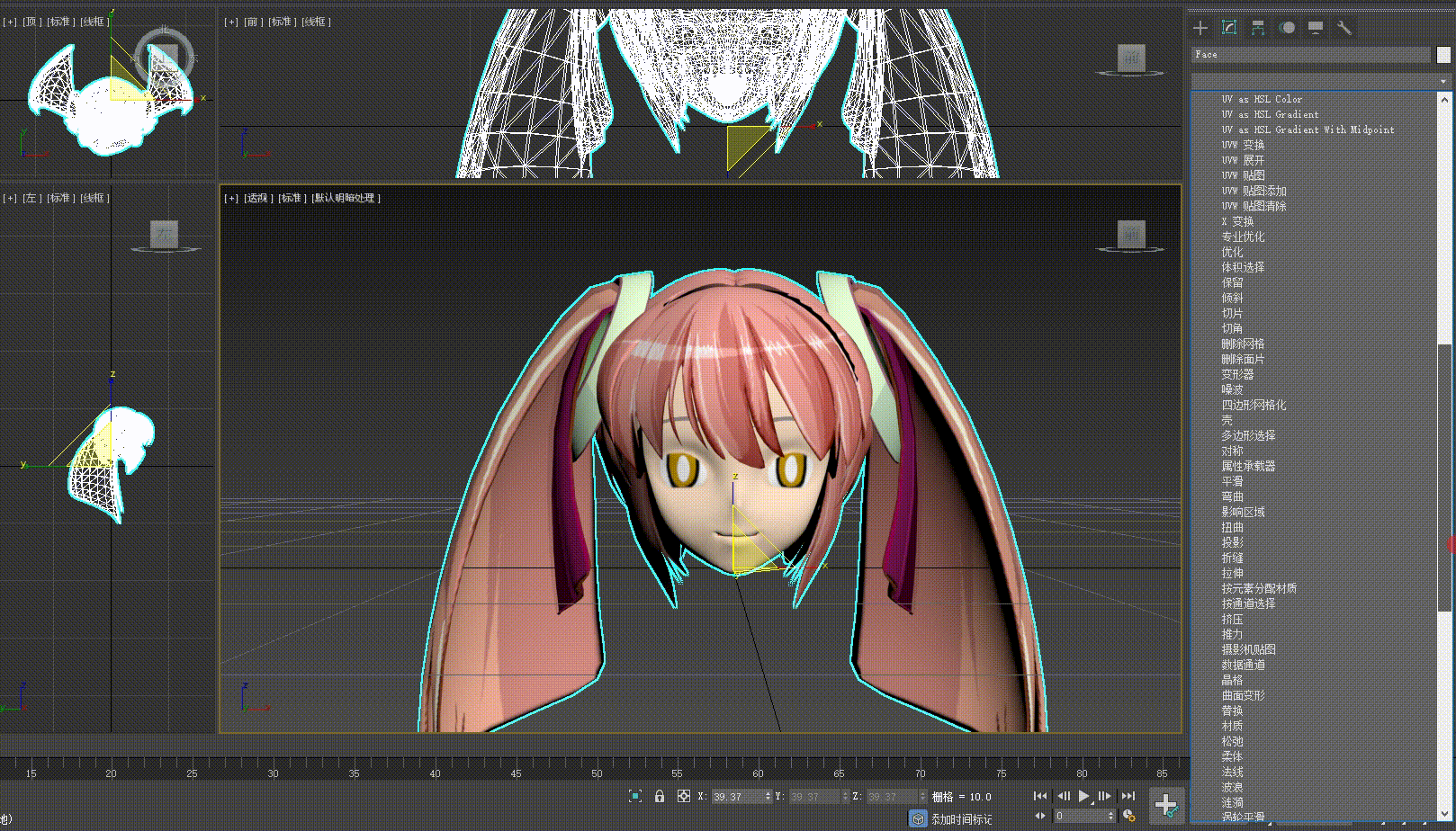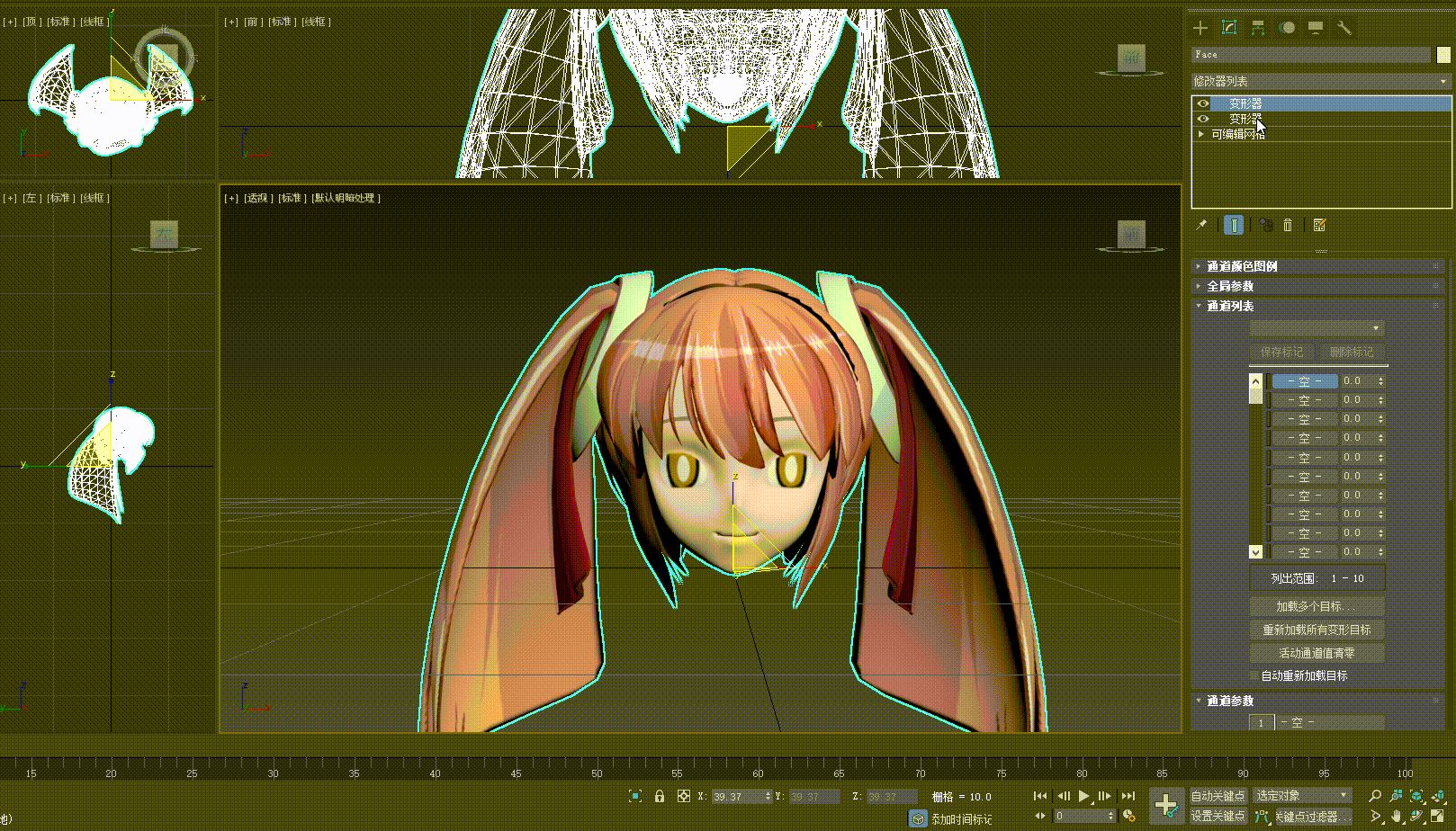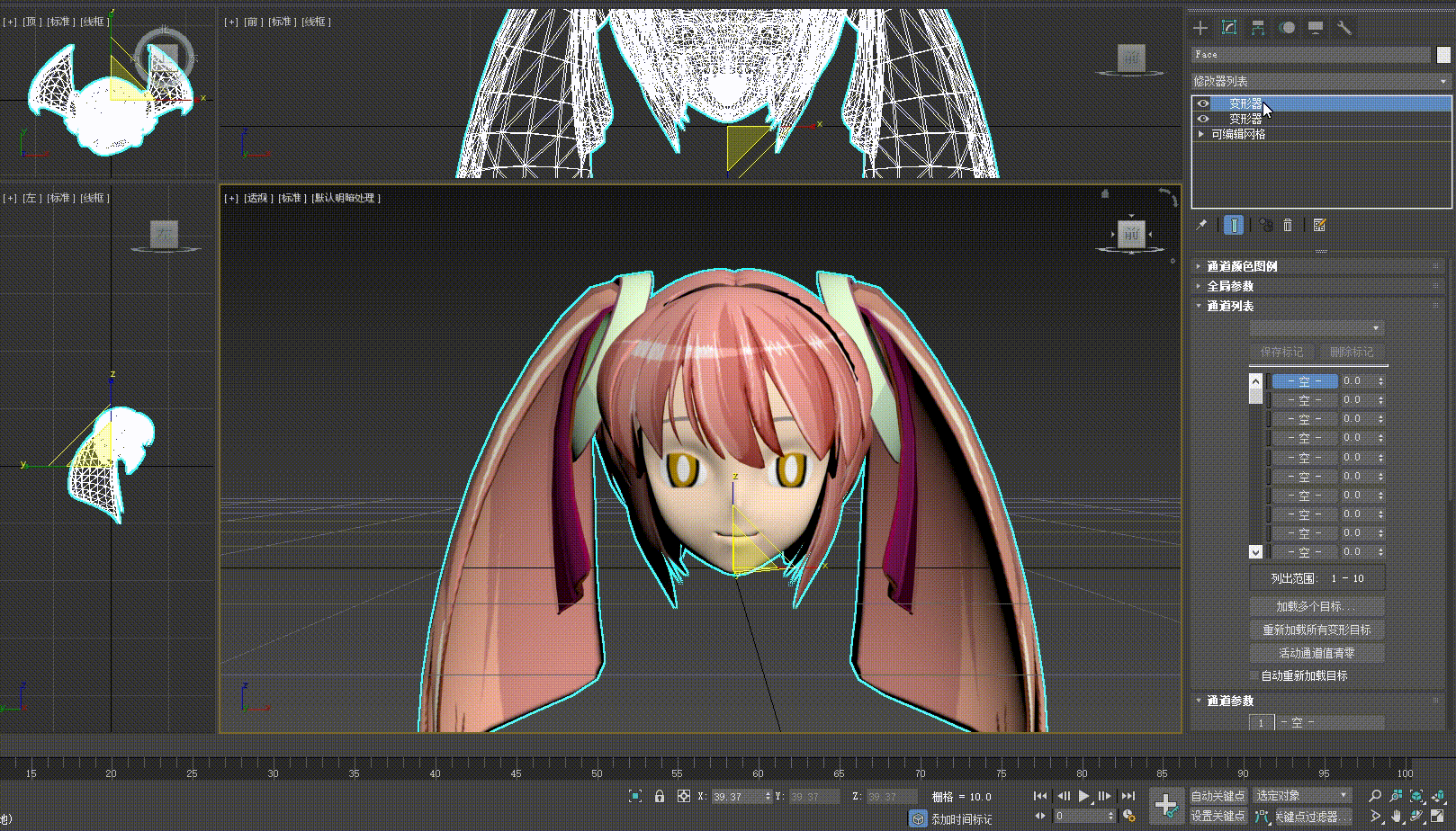
- 在创建的副本模型上更改相关变形效果
- 回到原始模型,选择变形目标创建变形数据,完成后更改数据的值我们就能够看到变形效果在模型上产生了
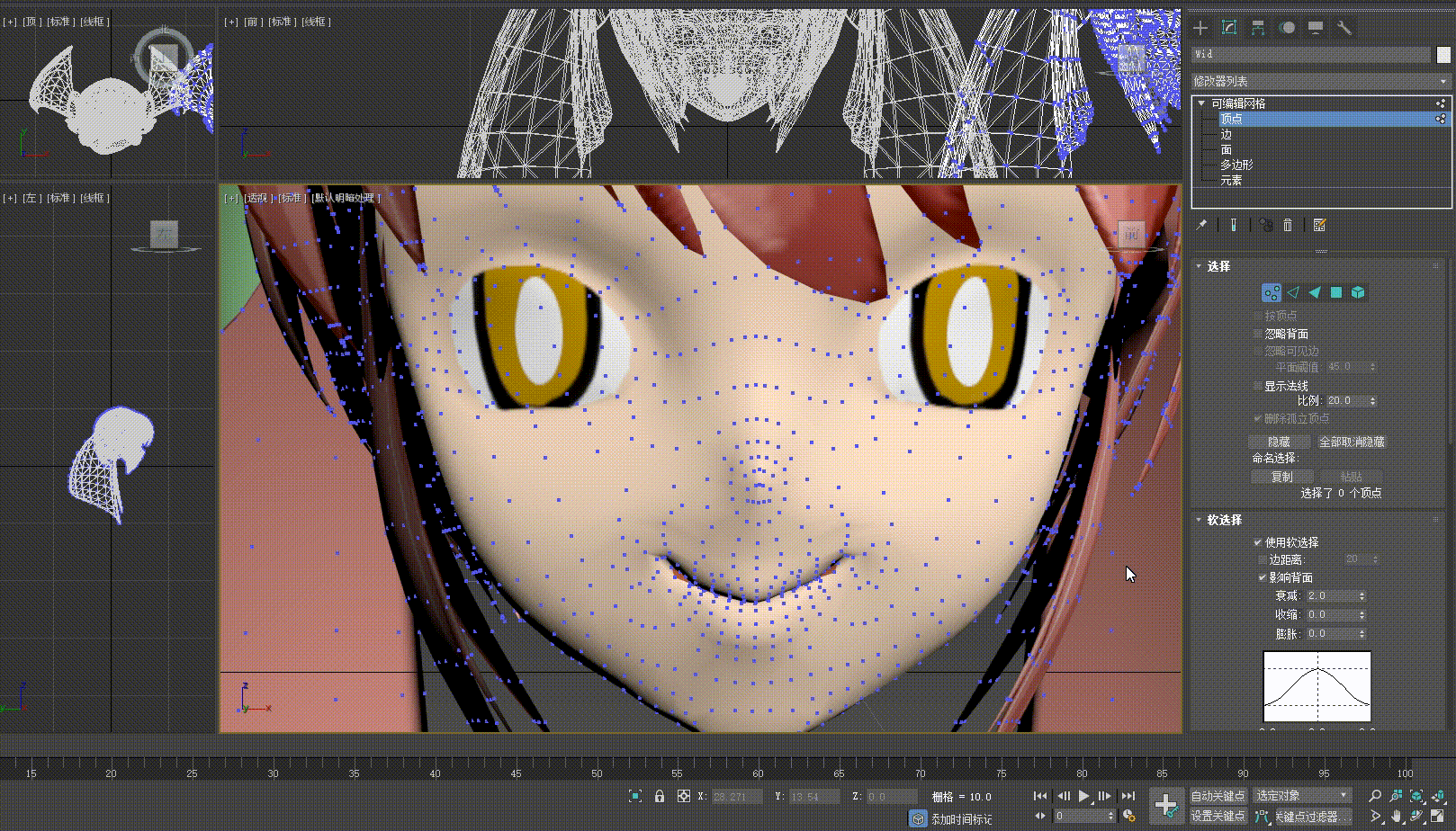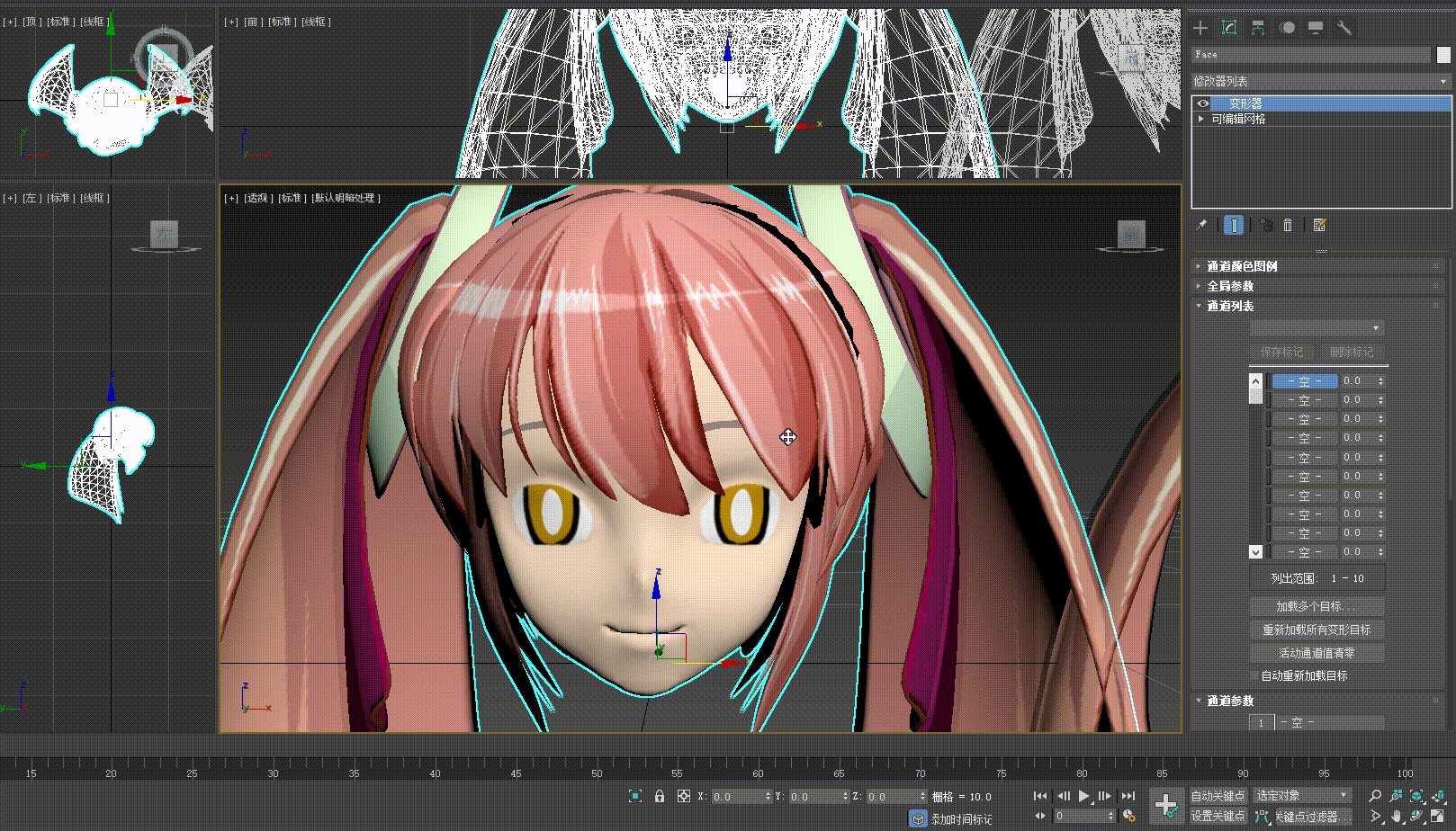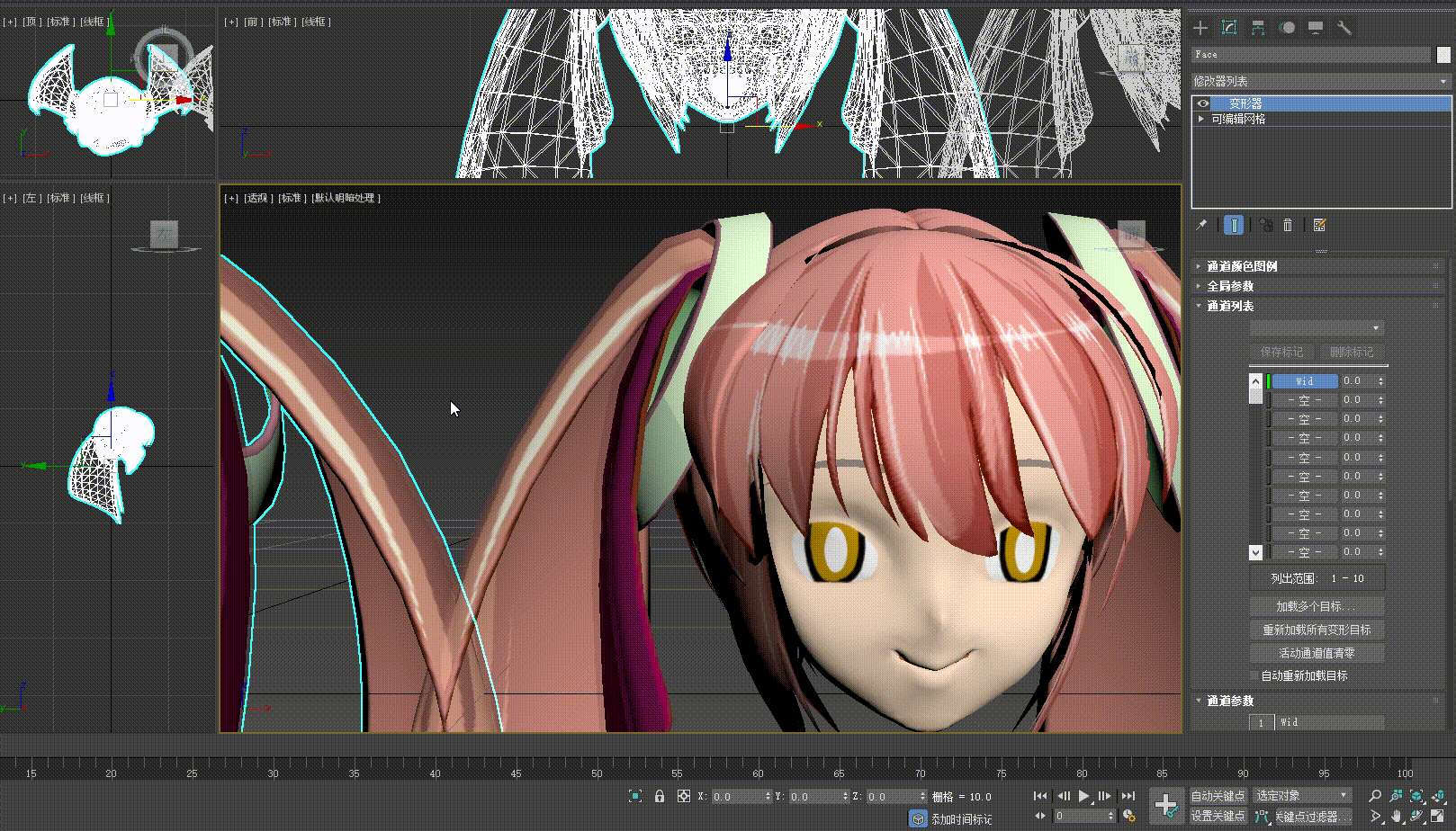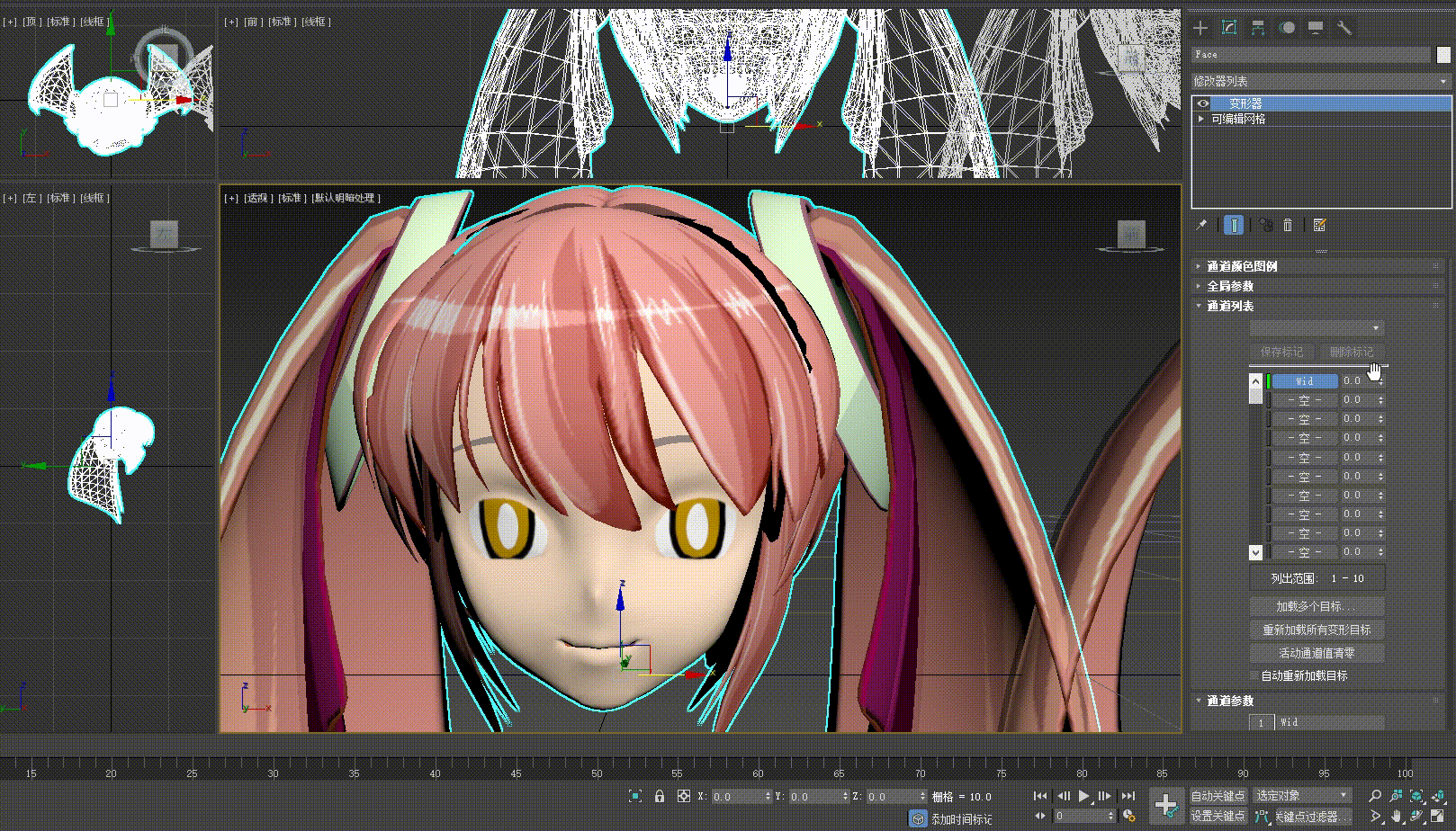
- 选择当前模型,进行导出,导出后的模型就可以为我们的口型效果提供变形数据
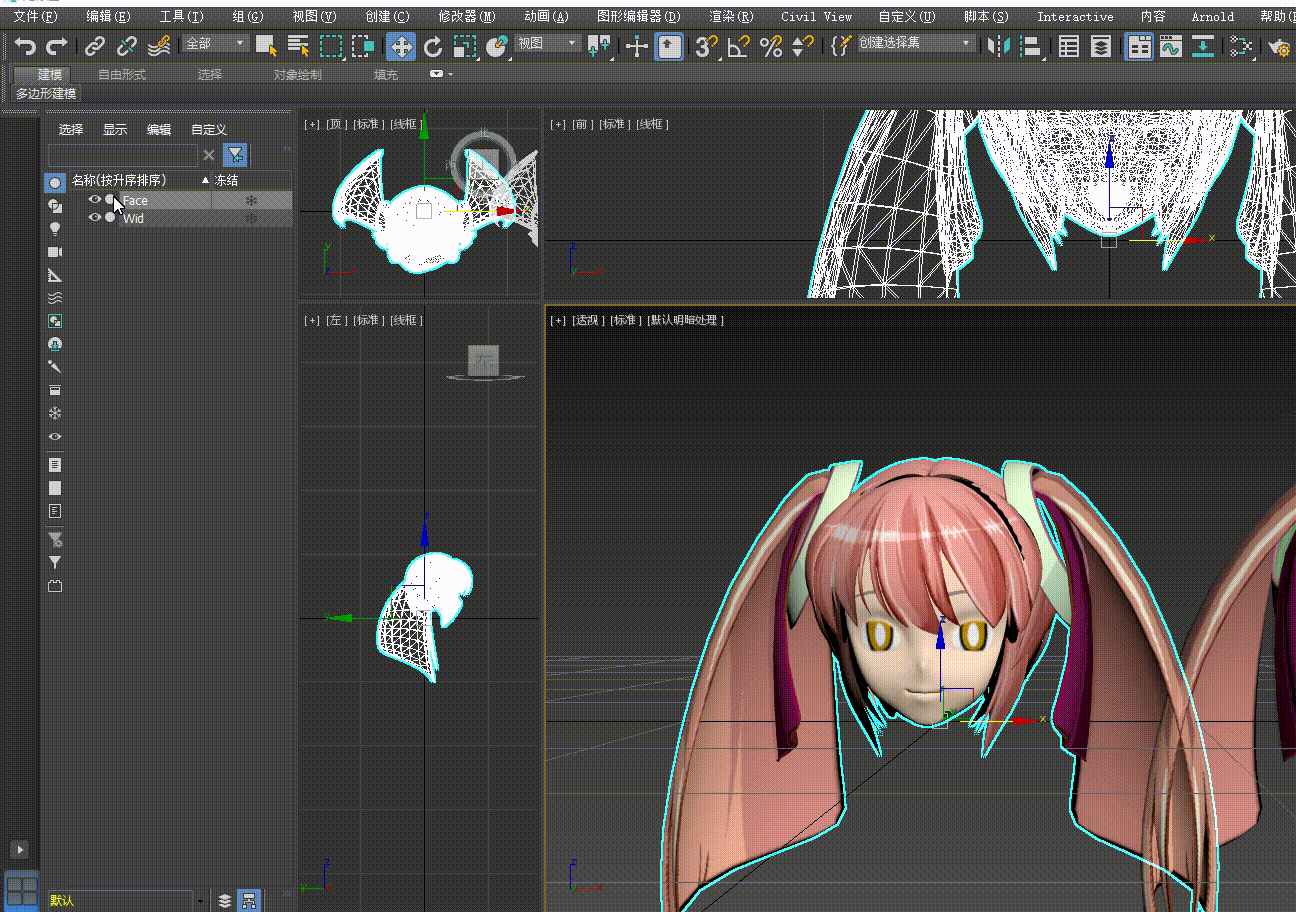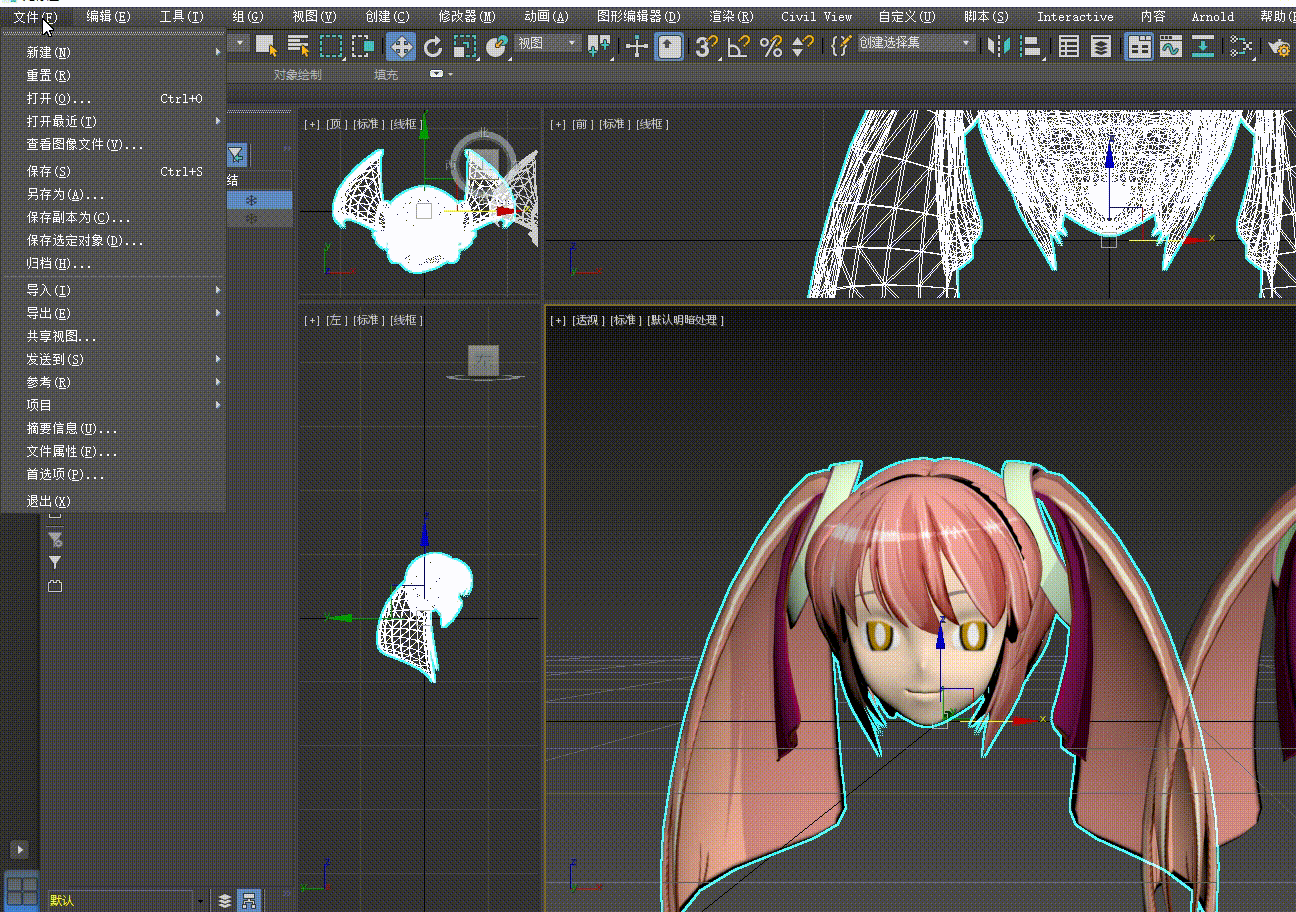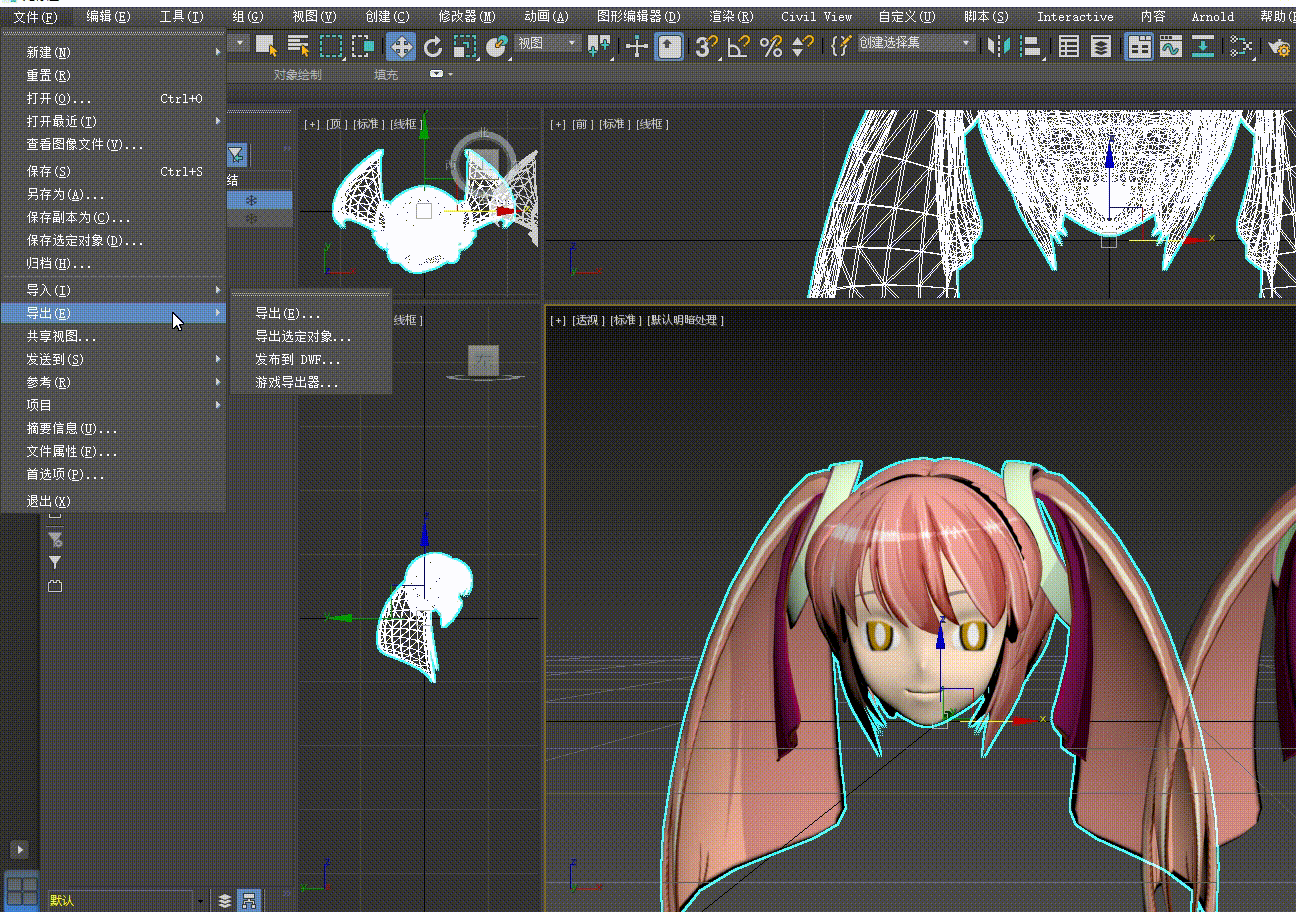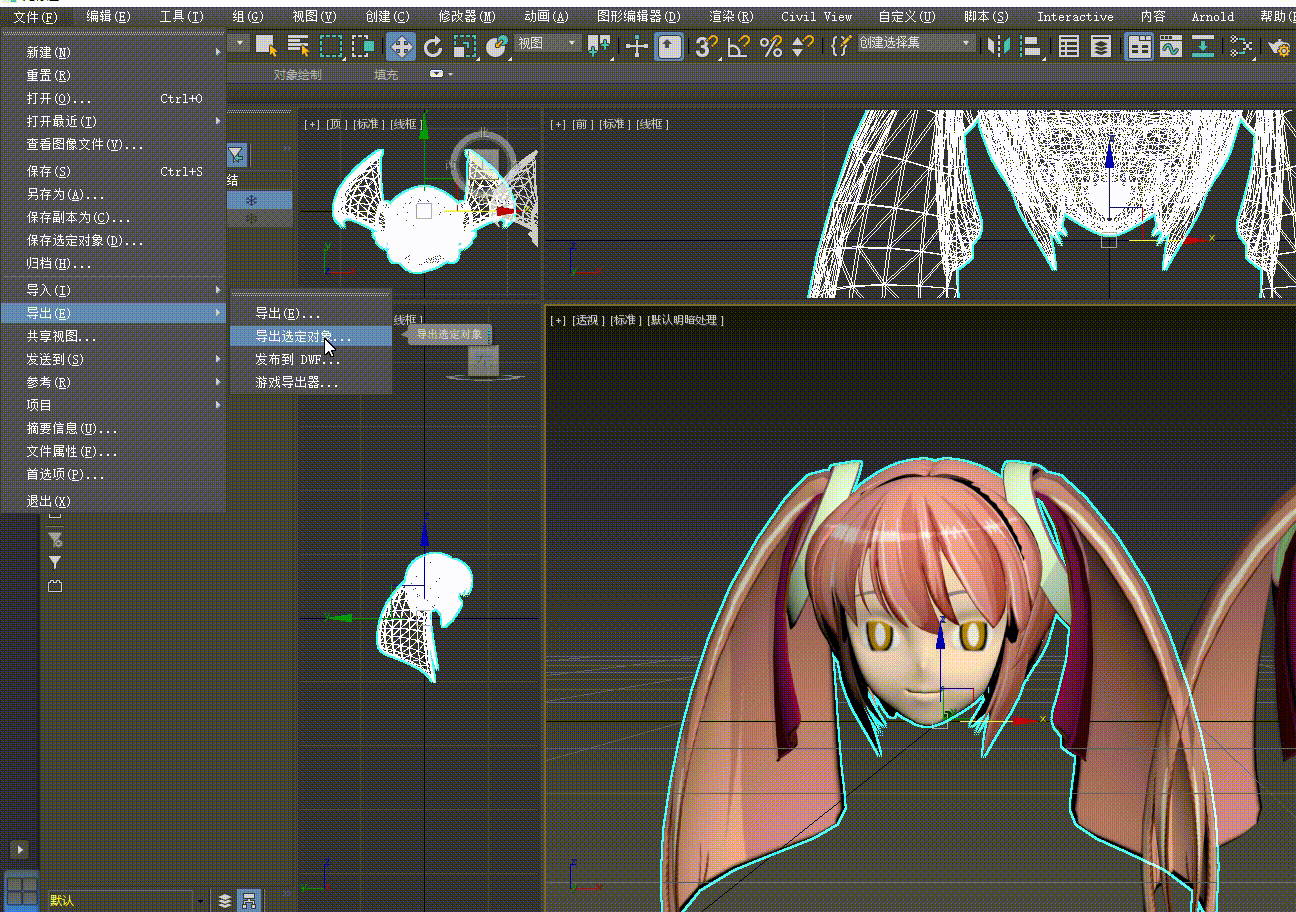
到此为止我们的模型数据就制作完成。
(3)·声音数据处理
完成了模型处理后,我们需要准备声音部分的处理。
ADX LipSync是跟随音频中间件ADX2进行连用,因此我们可以使用音频中间件ADX2来进行相关处理。
当使用当使用ADX LipSync时,将素材拖入到Track后,就能够看到声音文件对应的口型数据分析结果。
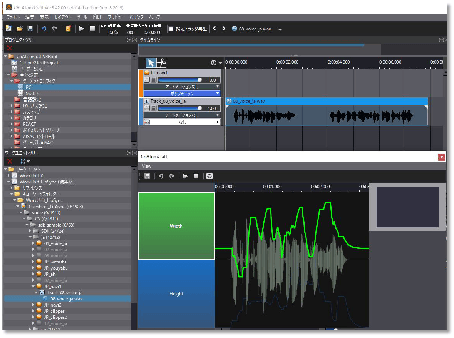
如上图,分析结果位于图片的右下方,我们可以看到相关的高度和宽度数据,这些是自动分析的结果,自动分析结果我们可以进行手动更改。
经过分析后,我们主要产出两种分析数据:
- 宽度高度模式,这种分析结果数据,对应于口型变化的宽度和高度结果,通过对声音进行分析,得到对应声音时刻变化的宽度和高度曲线,同时可以在ADX2中进行高度和宽度曲线的调整,以应对自动分析不满意的效果。
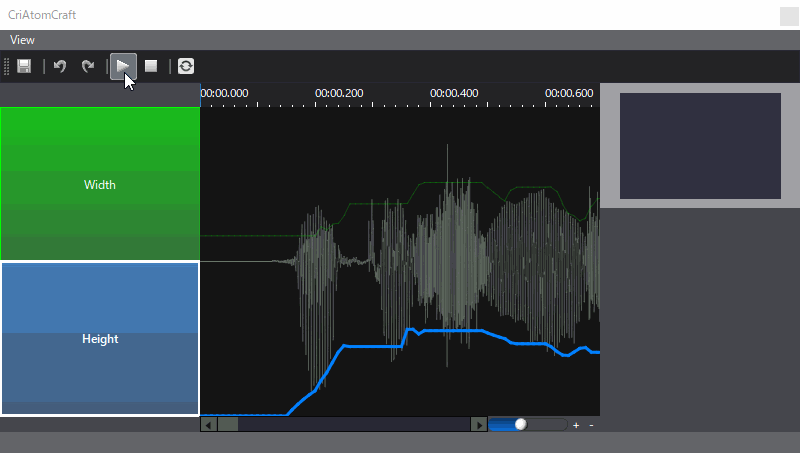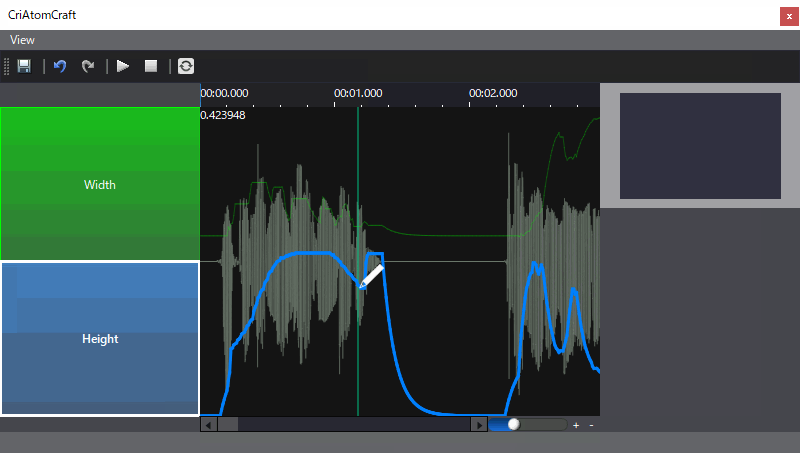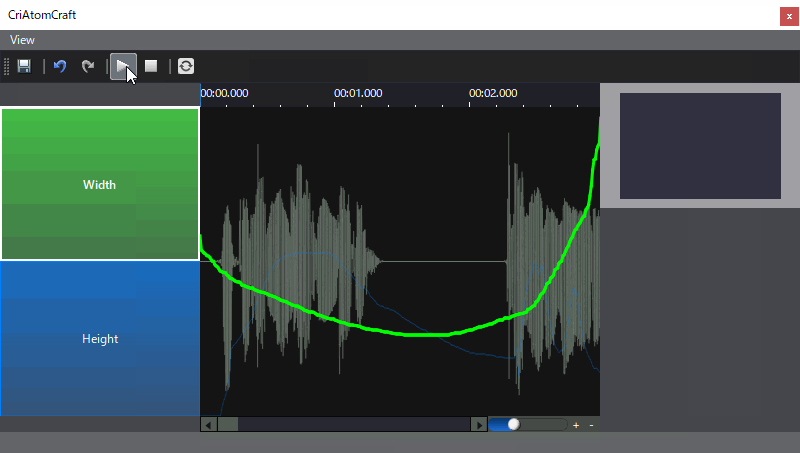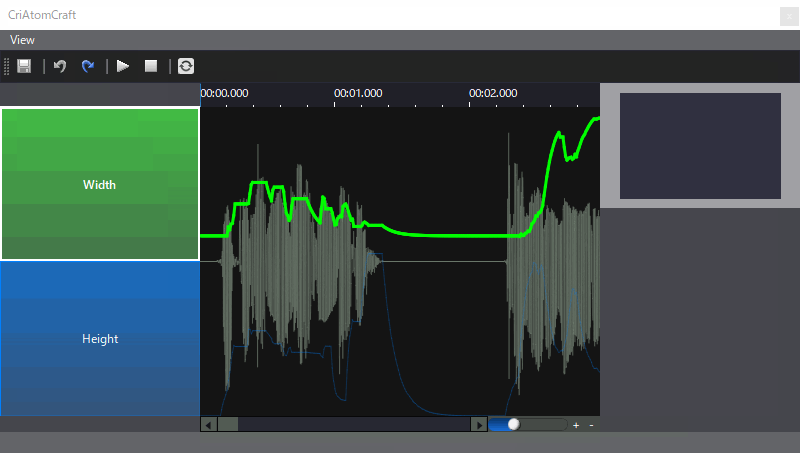
- 音素混合量分析模式,这种分析结果数据是分析语音中各个音素量的占比,通过占比决定各个音素口型的权重从而动态的变化模型变形效果,同样如果对于自动分析结果并不满意,则可以手动修改。
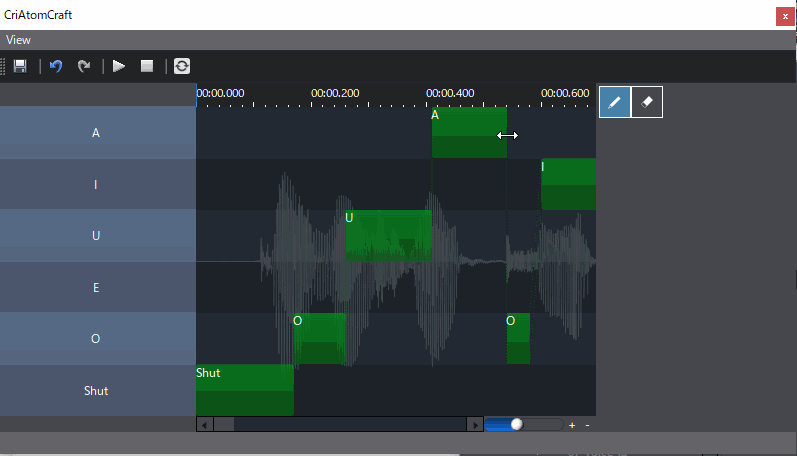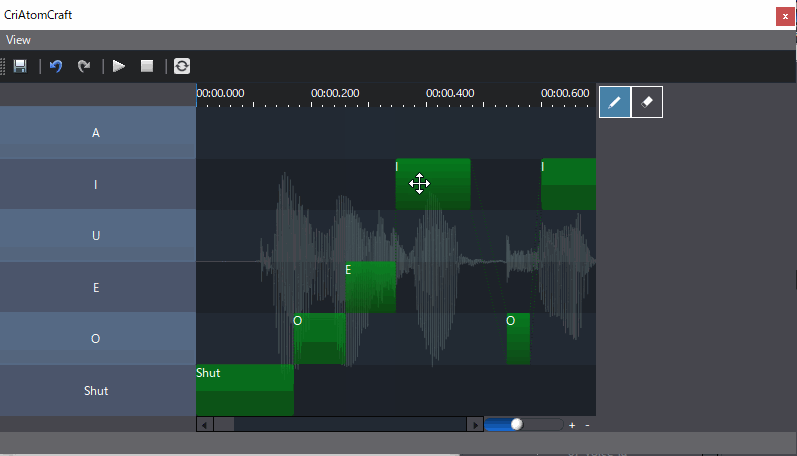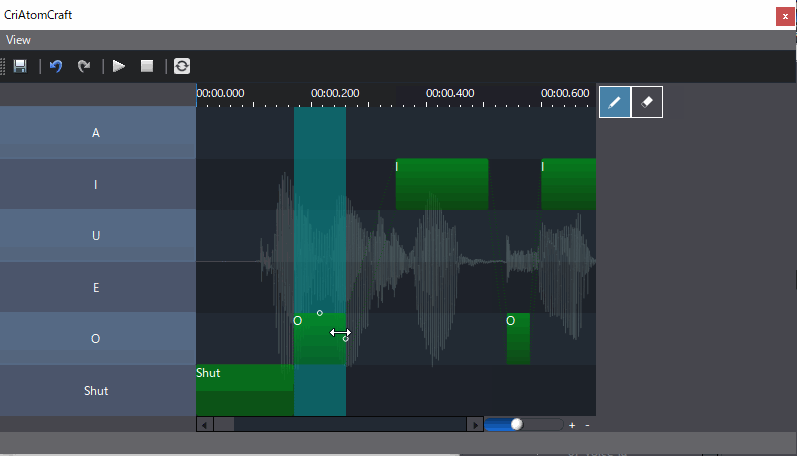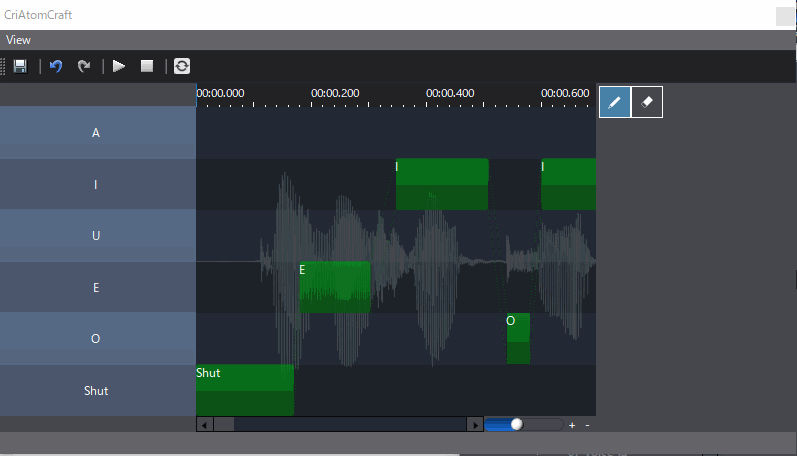
通过这两种数据,我们可以变更口型变化效果,来实现口型同步。
注意:
- 对于宽度和高度模式,没有任何语言限制,所有语种都可以使用,但是解析精度相对低。
- 对于因素量混合分析模式,和语种相关,目前提供日语的AEUIO几个元音进行解析,因此对日语的匹配度较高。
在使用ADX LipSync时,会和ADX2一起连用,由音频中间件ADX2导出资源文件,这些资源文件包含了音频中间件中制作的声音资源文件也包含了其中的口型数据结果。
完成了以上内容后,我们的资源文件就准备完成,下面我们将介绍如何使用这些资源文件来实现口型同步效果。
(4)·Unreal应用
准备好资源文件后,我们将资源文件导入到Unreal中主要包含两个文件,首先是创建的变形数据的模型文件,导入后我们在Unreal中打开,可以看到如下内容:
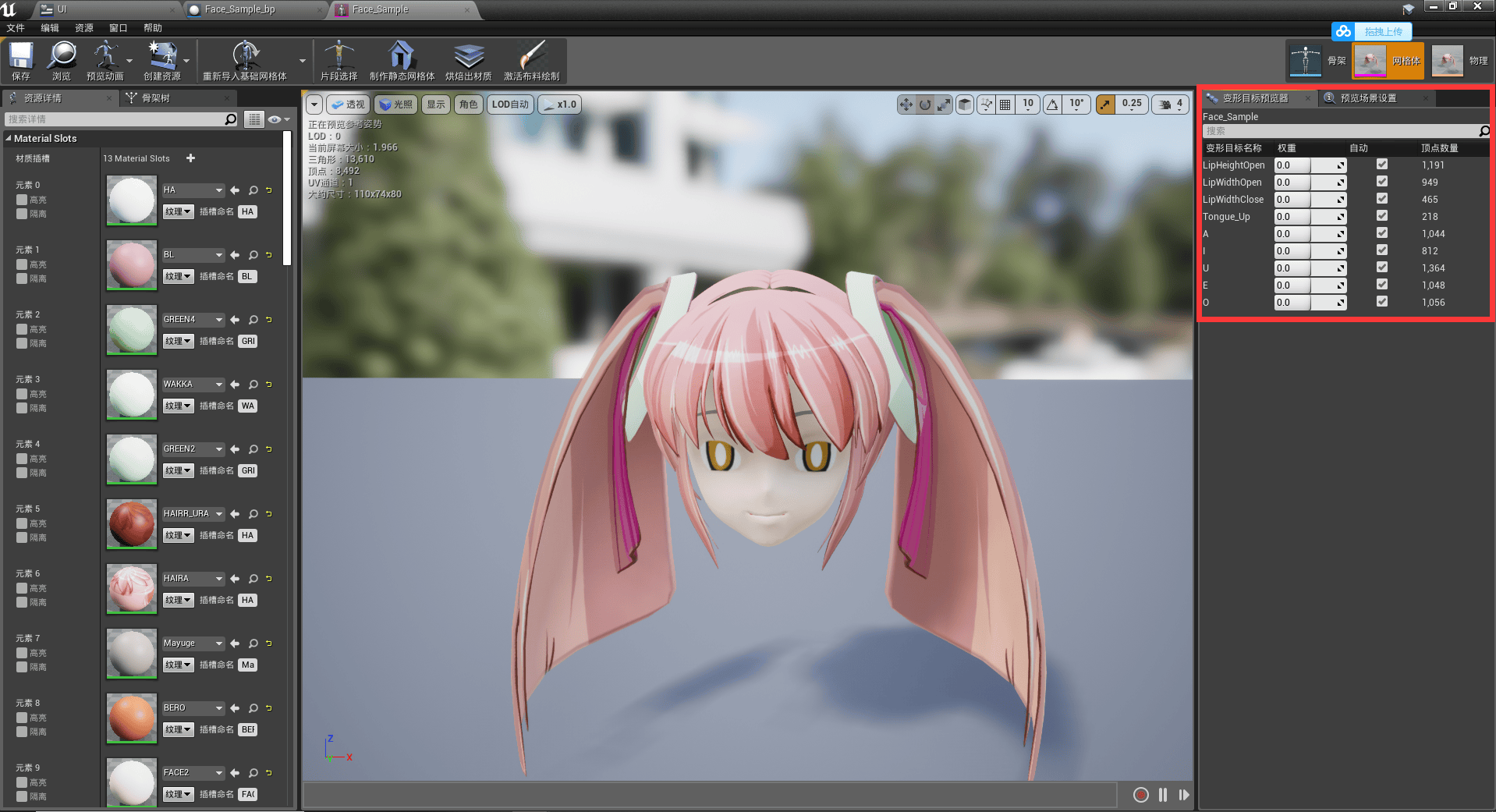
我们可以看到,在3D Max中创建的变形数据已经显示在Unreal中了。此时我们在Unreal中更改相关参数也能看到参数对模型产生的变形效果。
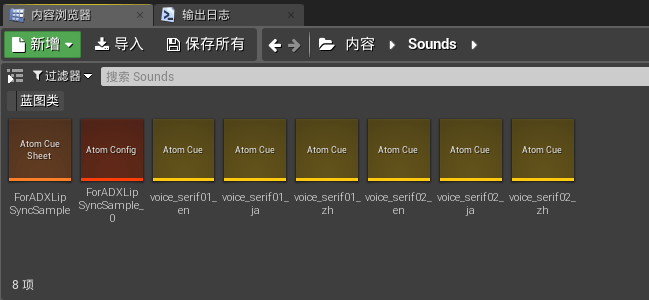
上图显示的是导入的ADX2的声音资源文件,导入后会自动显示出创建的Cue(事件)内容。
我们将使用这些Cue内容,以及相关接口创建蓝图,用以播放声音时变更模型的变形效果完成口型和语音的匹配。
下面我们开始制作口型同步内容。
①·蓝图类创作
选择我们的模型文件,创建蓝图类:
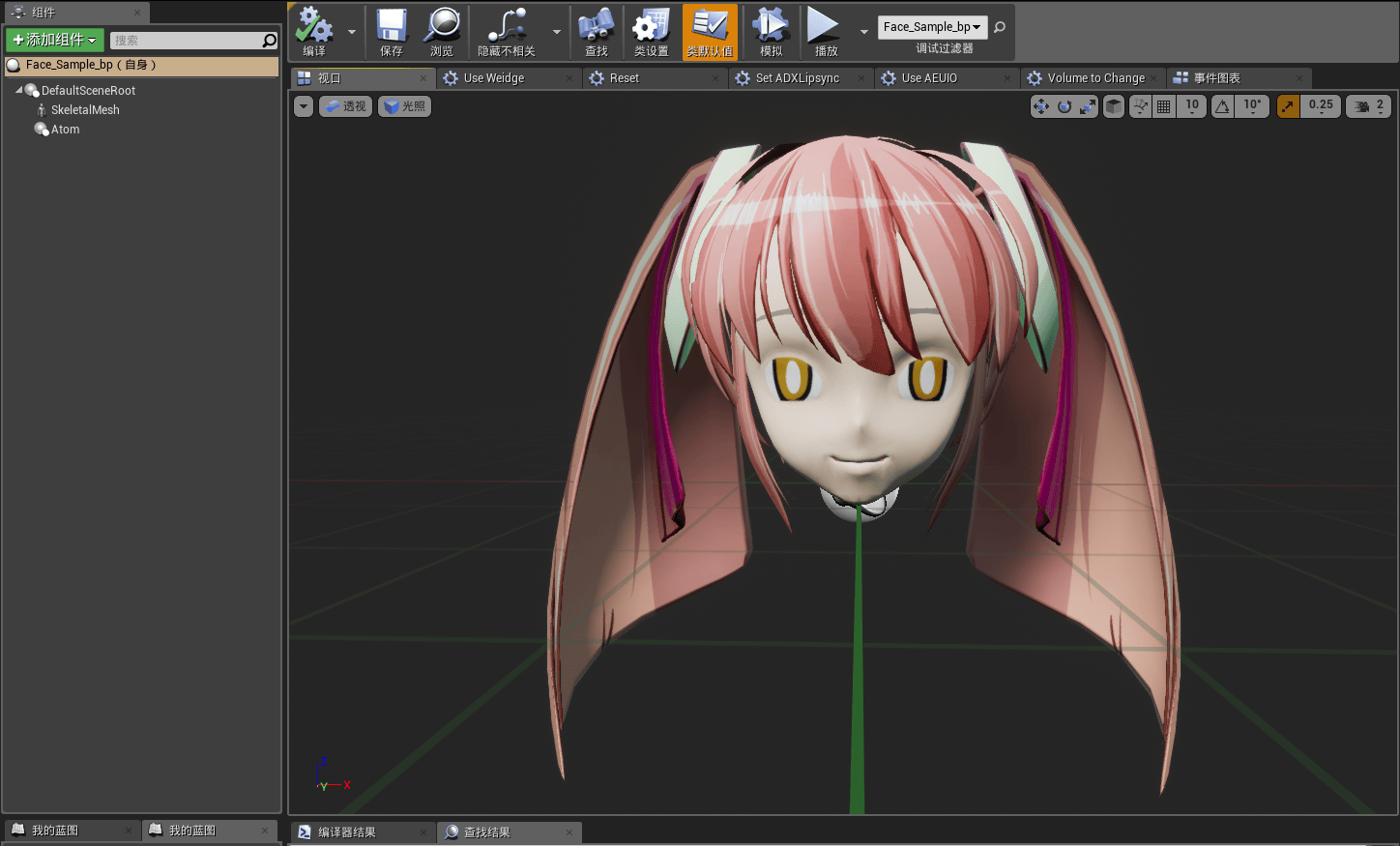
同时创建Atom Component,Atom Component主要用于Cue的播放,由于Cue中包含wav信息,而ADX LipSync则是分析Cue中的声音信息生成对应的口型数据,因此我们需要播放相关的Cue来同步口型。
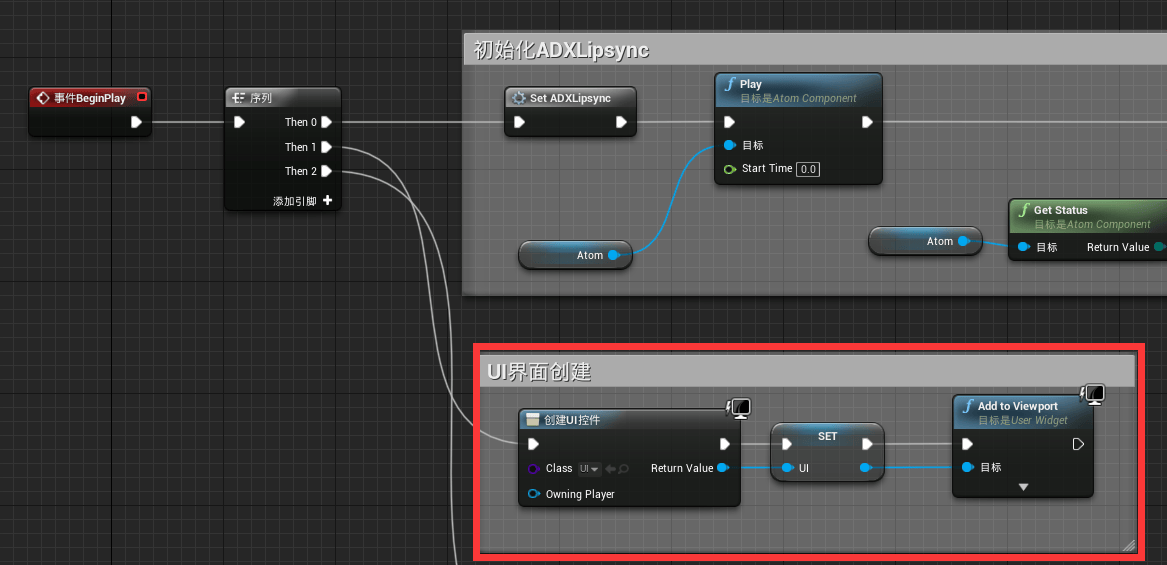
②·初始化LipSync
蓝图类创建完成后,我们要进行蓝图功能的创建,首先我们需要创建初始化LipSync相关逻辑,我们创建一个名称为Set ADXLipSync的宏,该宏用于初始化LipSync,
逻辑如下:
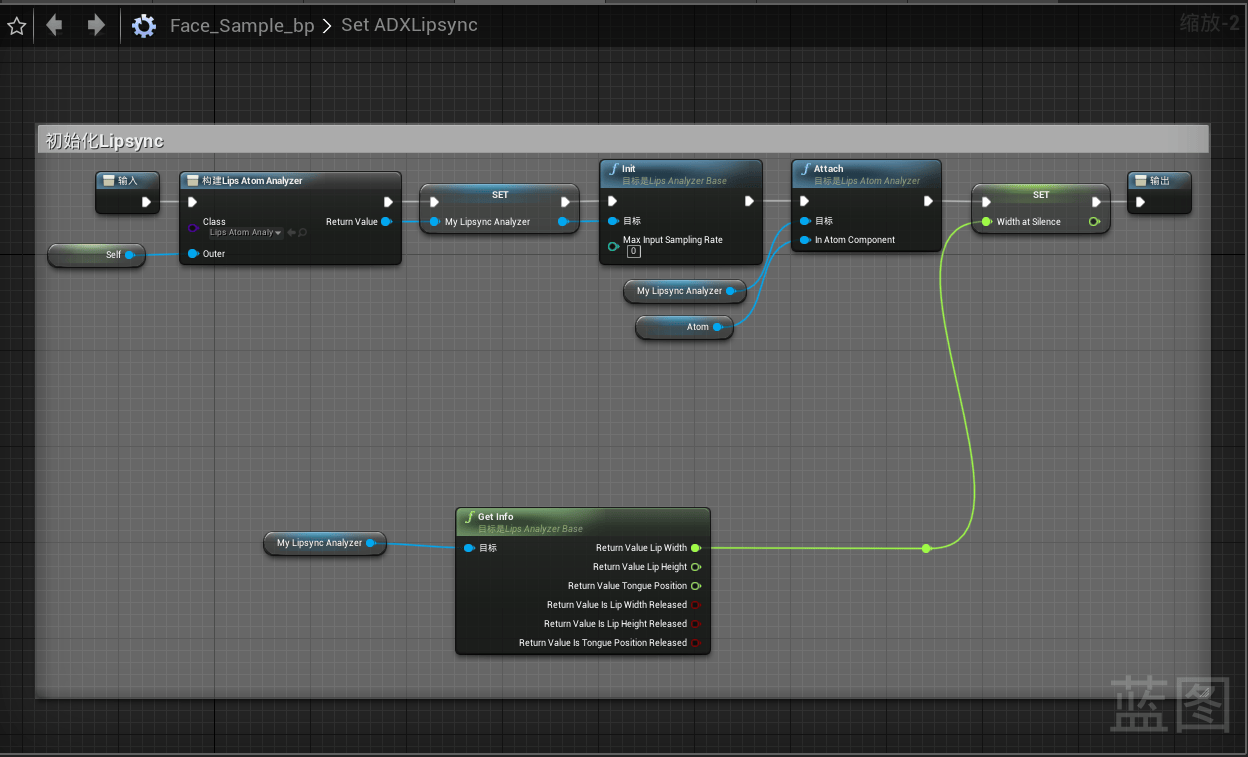
创建了构建Lips Atom Analyzer,并将其设置为变量,便于调用。并添加Init相关,需要注意的是Init必须要创建Attach前。
而后用Get Info并将Lip Width的值设置为参数的原因是当处于无声状态时,口型的宽度并不一定等于0,这些由美术在制作模型变形数据时决定。
初始化创建完成后,我们回到事件图表中,并创建下面蓝图内容:
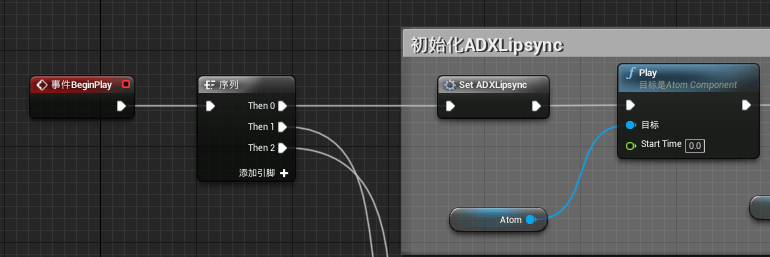
通过Event BeginPlay我们执行了Set ADXLipSync宏,初始化相关内容,同时我们Play Atom使得运行时能够直接听到声音效果。
③·口型分析模式创建
初始化完成后,我们需要创建口型分析模式,并且通过口型分析模式来决定我们怎么使用模型的变形效果,通过分析的声音口型数据动态的变更模型的变形参数来实现口型变化效果。
因此我们创建两个宏分别对应宽度高度模式,音素量混合分析模式,为了做对比,我们再创建一个宏用于音量控制。
宽度高度模式相关逻辑如下:
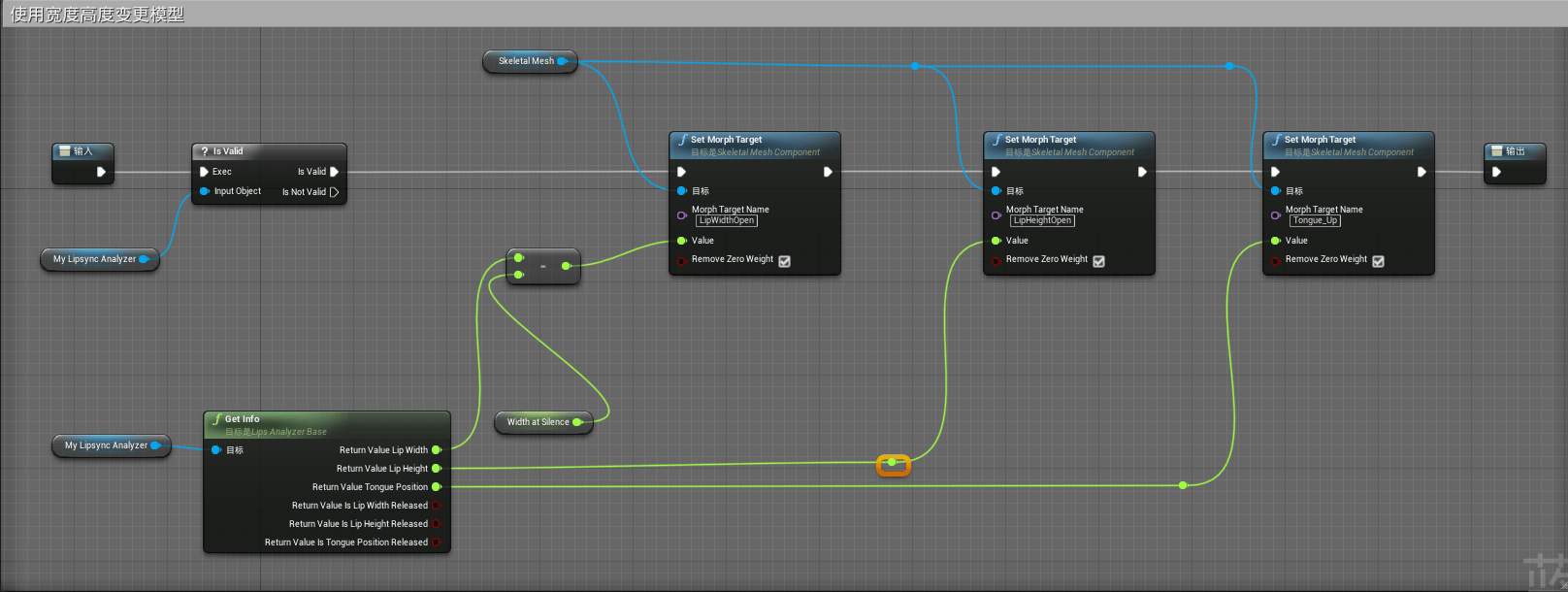
我们使用了Get Info的相关数据,使得Lip Width控制模型文件的LipWidthOpen参数,Lip Height控制模型的LipHeightOpen参数,使用Tongue Position控制模型的Tongue_Up参数,当Info的数据跟随声音进行变化时,能够同时变更模型相关的各个参数值变化,引起口型变化。
音素混合量分析模式相关逻辑如下:
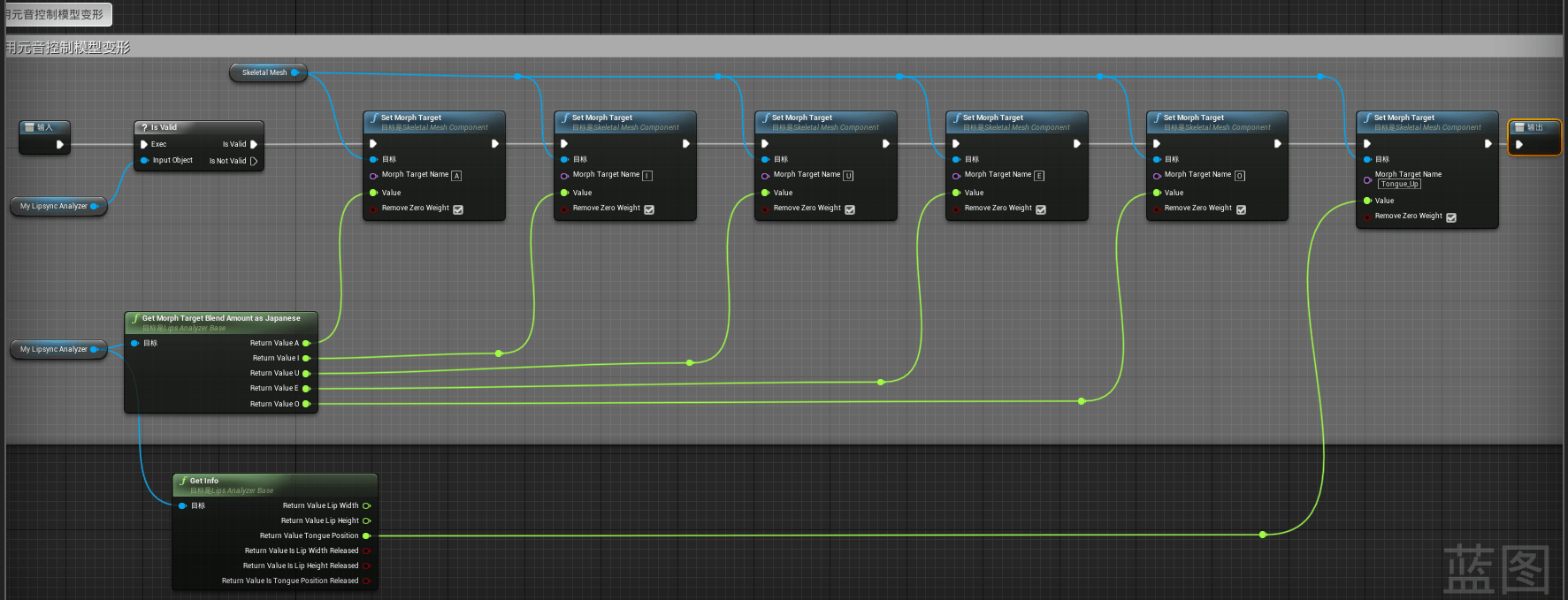
与高度宽度类似,只是使用的数据不同控制的模型变形参数不同,同样可以控制模型的变形参数实现口型的变化。
音量模式相关逻辑如下:
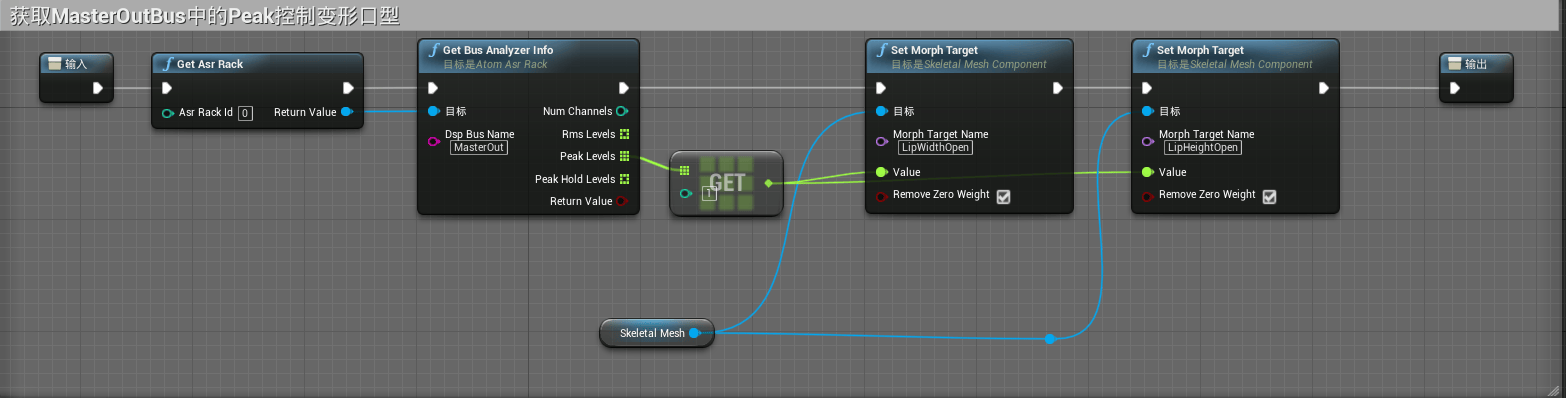
音量模式我们创建的目的是为了进行对比,以此来通过模式切换非常方便的看到不同模式下口型的效果。
音量模式下,我们采用的是通过Bus中的Peak Leavels值来变更模型的LipWidthOpen以及LipHeightOpen参数。
通过上述步骤,我们完成了创建宽度高度模式、音素混合量分析模式以及音量模式的宏,下面需要创建如何使用这些宏来变化口型效果。
④·界面显示及其功能创建
我们想通过Unreal直接进行运行中更改模式,并且显示相关Cue(事件)名称以及当前的分析模式以便于我们进行测试和效果演示,因此我们创建一个UI控件蓝图,并添加以下内容:
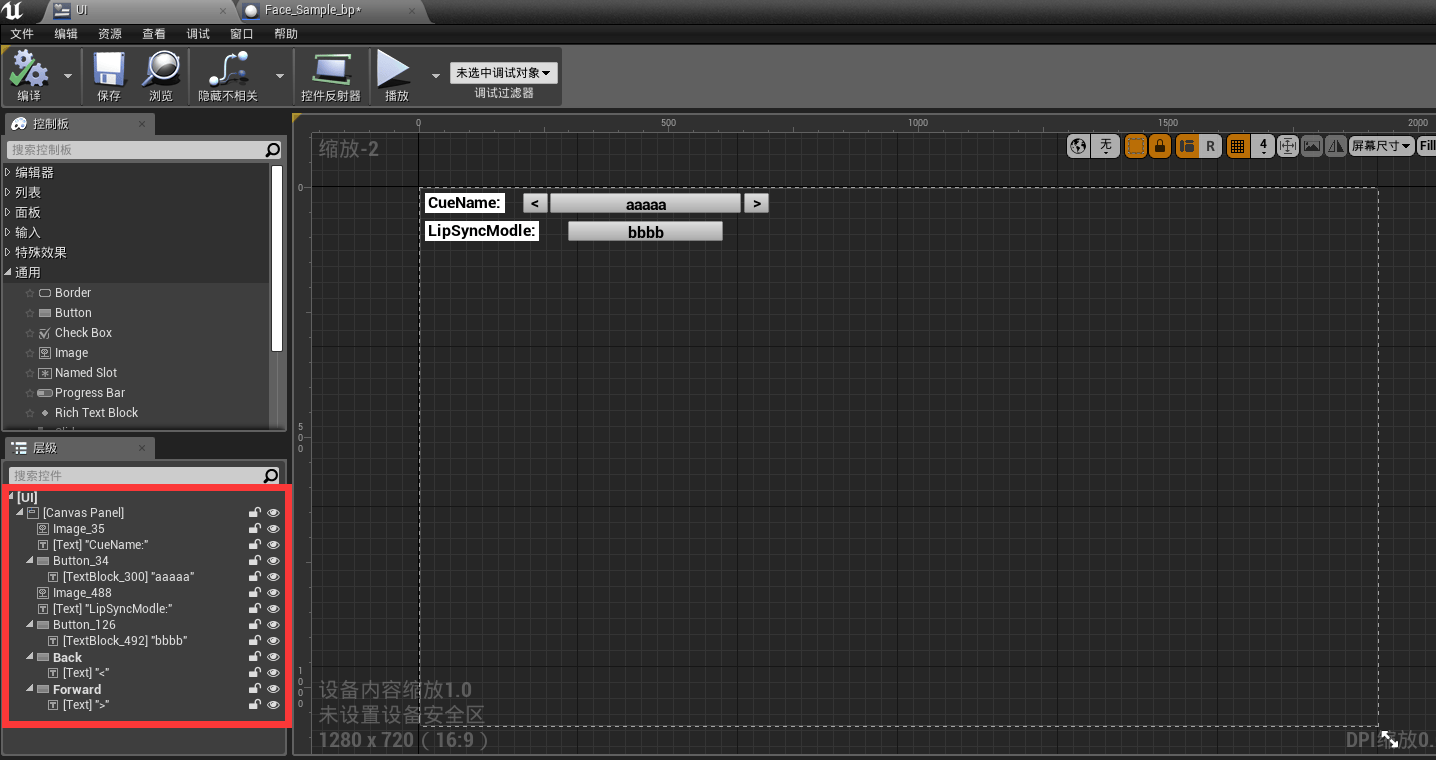
完成后,我们选择"TextBlock300"和"TextBlock492"并做如下的显示TXT绑定内容:
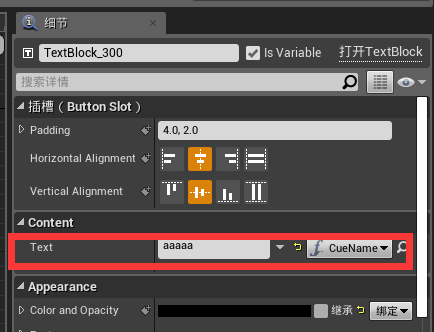
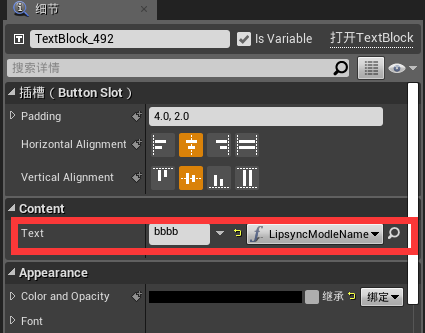
同时创建两个String类型的参数分别为:CueNameParam以及LipsyncModleNamePara用于存储Cue的名称和当前模式的名称。
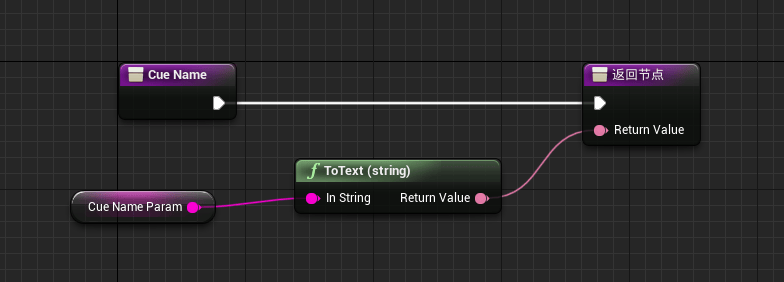
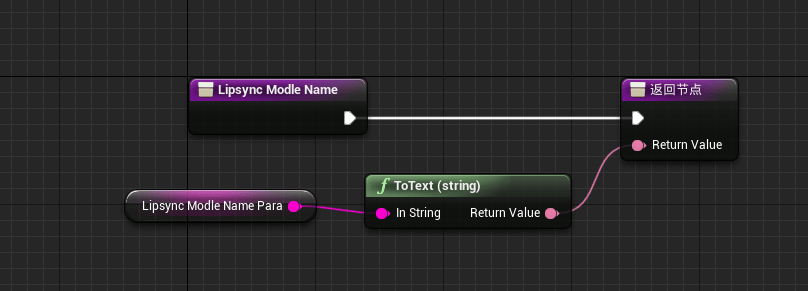
回到我们的蓝图类中,我们已经完成了3个宏的创建,并且拥有了相关UI,那么下面需要将UI创建在界面上,并且进行模式的更改:
如上图所示,我们创建相关UI控件,使之显示在运行中的场景中。
同时为了更改口型分析的模式,我们需要创建三个不同的bool类型变量,

这三个bool类型的参数用于我们的模式选择。
我们再创建三个自定义事件,用于控制模式更改时的bool类型值变化以及创建的UI中的当前模式的显示文本:
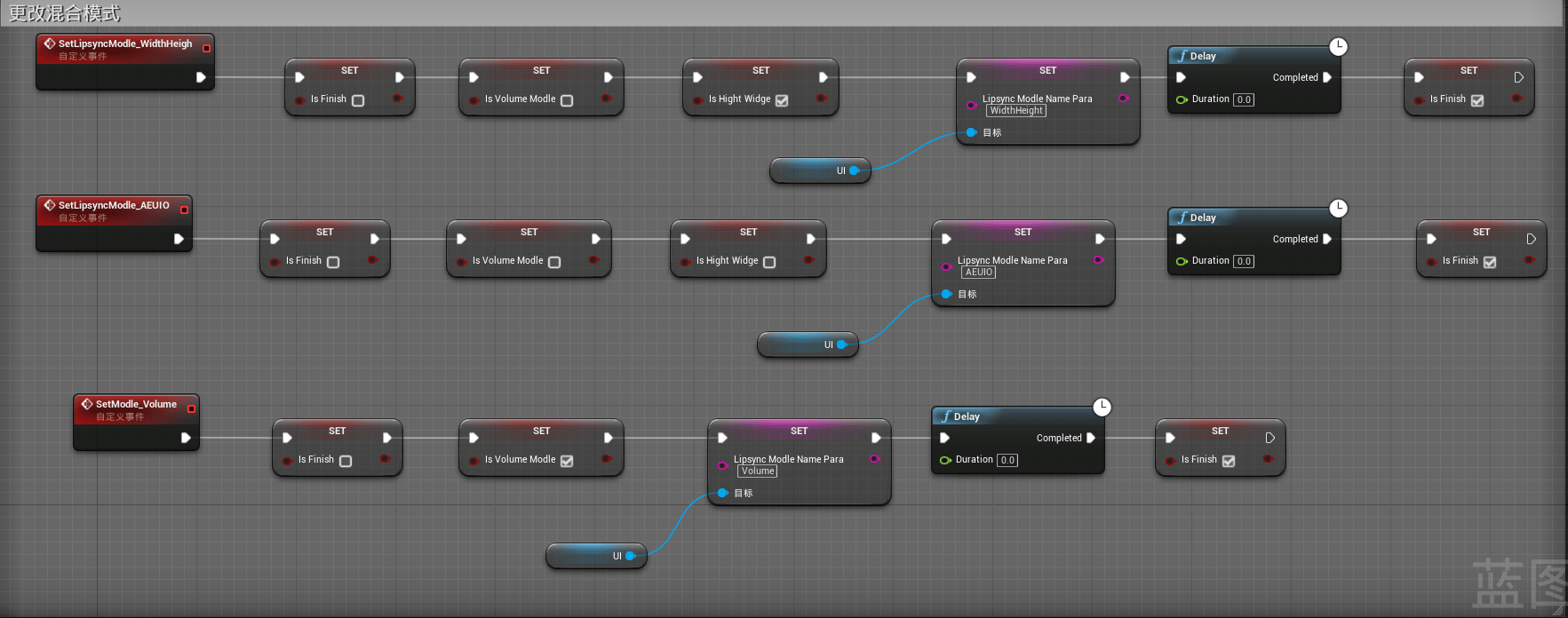
在上图中我们可以看到,当执行不同的自定义事件时,会更改相关的bool参数值,同时会设置UI中的LipsyncModleNamePara参数显示。
完成上图中内容后,我们拥有了能够改变bool值的参数,而我们想通过bool值参数来变化混合模式的类型,下面将做相关内容逻辑:
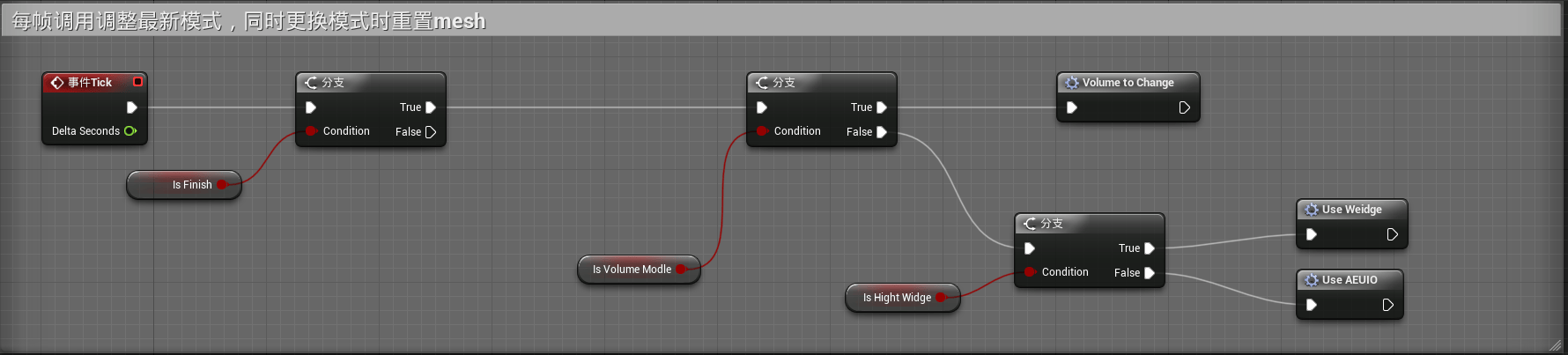
我们通过调用Event Tick使得每帧刷新,通过三个bool变量选择最终的混合模式,而在混合模式中,由于每帧刷新,因此会不断的根据Cue的声音内容变更相关的info信息,从而每帧更改模型的变形参数,形成最终的口型效果。
完成上述内容后,我们仅仅是完成了各个口型模式的逻辑,以及如何选择任意一个模式的逻辑,但是没有选择相关模式的触发内容,因此我们回到UI控件蓝图中:
在控件蓝图中我们选择如下的按钮并且使用其点击事件:
鼠标点击后将会跳转到事件图表中,我们做如下的逻辑:
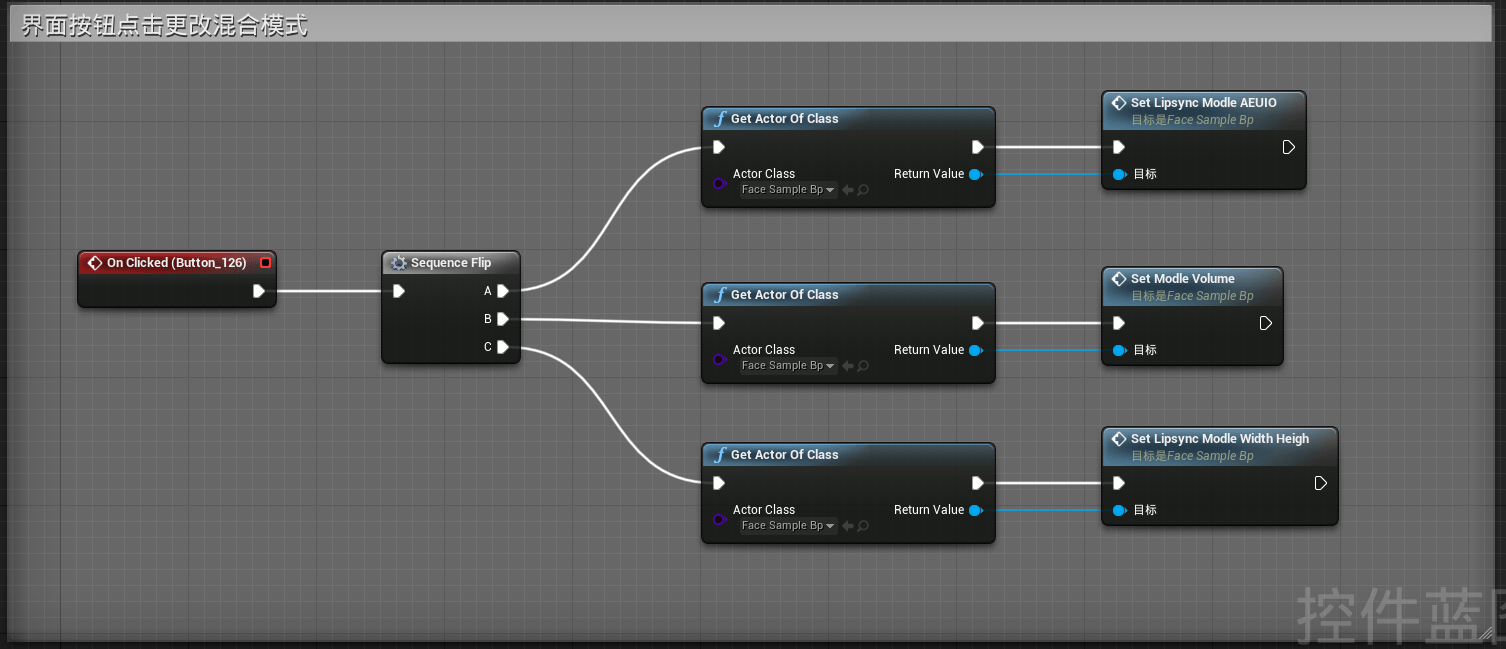
可以看到我们在控件蓝图中调用了刚才在模型蓝图事件图表中创建的三个自定义事件,如此一来我们每次点击按钮都会按照顺序执行三个自定义事件中的一个,以此来更改设定的bool参数值,从而在Event Tick调用时转变调用的混合模式宏,驱动不同的模型变形参数效果。
注意:在上图中的Sequence Flip是笔者自己定义的流程控制宏,用于每次执行时按照顺序依次执行一条,如此反复,相关逻辑如下:
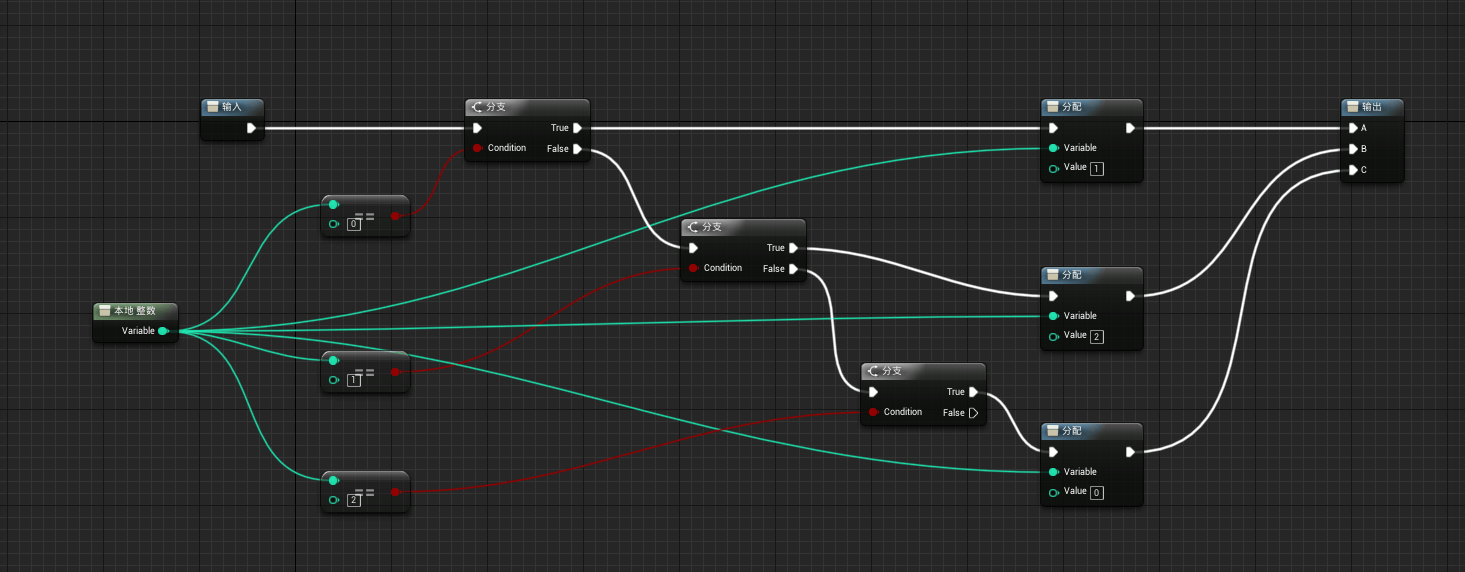
按照上述内容完成后,我们就可以得到每次点击按钮就会变化混合模式,当声音播放时我们就能够看到不同模式下口型变化效果进行对比和分析。
而各位在实际测试中会发现,当我们变更模式时有时候口型会变得非常大,这是因为在我们点击按钮变更模式时,所有数据依然是当前点击时的数据,因此会被记录并且保持不变,当使用其他模式时,其他模式下的声音数据引起的口型变化效果和当前点击时的口型变化值相叠加导致口型变大。
为了解决这一个问题,我们需要在点击按钮变化模式时,将所有变形效果重置为0,因此我们创建Reset宏,逻辑如下:
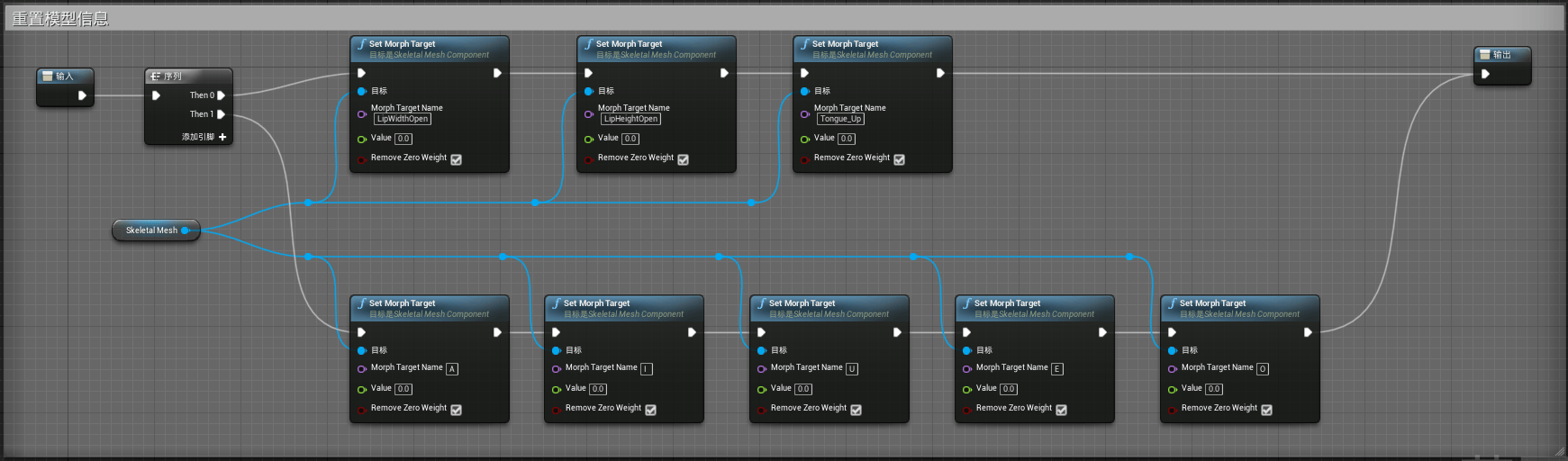
如上图,Reset宏的作用是当执行该宏时,会重置所有模型的变形参数值,使得其回归到0,当被其他声音数据再次驱动时能够不记录前一个数据的值而引发口型变大效果。
同样我们需要在Event Tick时进行处理:
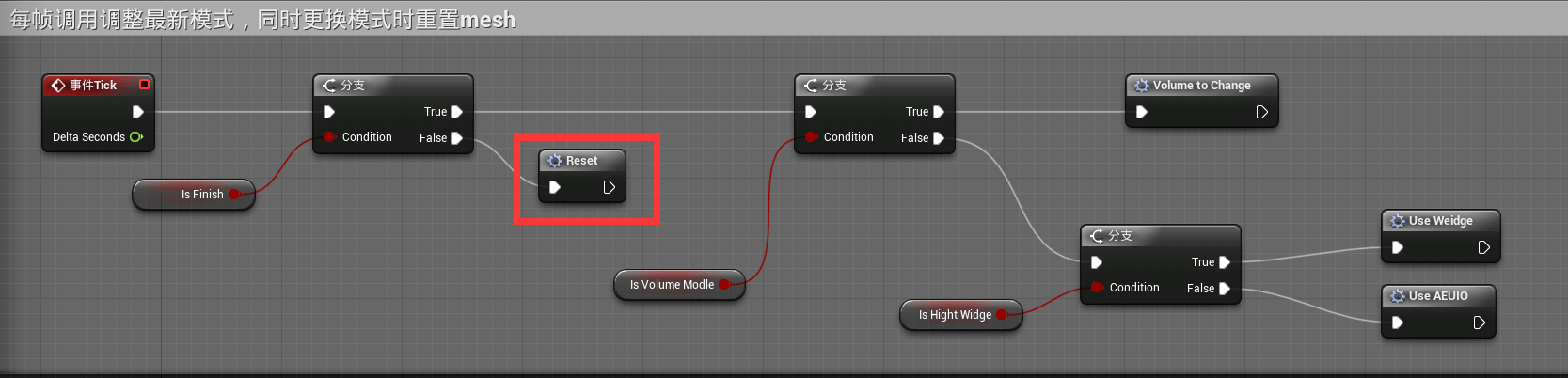
如此一来,当每帧调用时,每次更改模式,都会触发一次Finish为False而执行一次Reset,通过Reset我们将所有模型的变形数据还原修复口型变大的问题。
当完成上述内容后,针对如何使用ADX LipSync的介绍已经完成,我们可以通过上述内容测试和制作相关口型同步原型。
但笔者这里再进行一步优化使得能够在运行中时刻测试不同语言在不同模式下的表现。
⑤·优化内容
由于ADX LipSync是由声音中间件ADX2创建的数据进行分析后得到的数据进行口型处理,那么我们可以创建相关的变量用于存储不同语种的Cue内容,使得在运行中可以实时切换便于测试。
首先我们创建一个名称为CueList,变量类型为Sound Atom Cue的数组,并将不同语言的Cue内容添加到数组中:
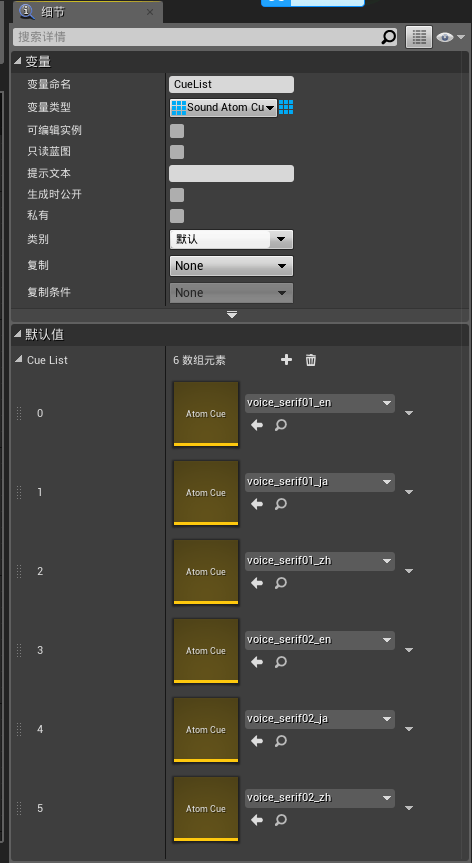
完成后我们再创建一个名称为CueChoice的自定义事件,并添加如下逻辑:
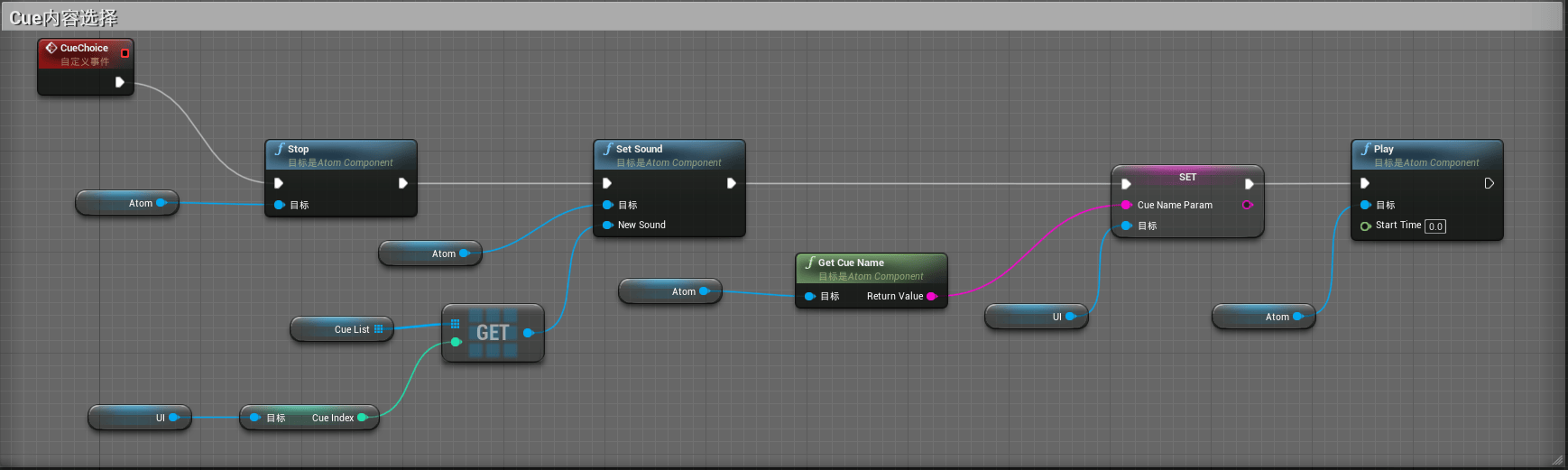
其中从UI中获得的Cue Index稍后介绍,需要在UI控件蓝图中进行创建。
创建上述的逻辑目的是为了当我们点击一个按钮时,能够动态的选择其上一个或者下一个CueList中的Cue进行播放,同时将Cue的名称显示在界面上。
CueIndex参数是需要在UI控件蓝图中进行创建,因此我们回到UI控件蓝图中,创建一个整型的名称为CueIndex的变量:
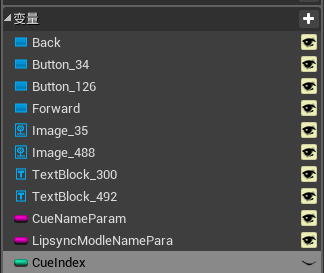
此变量主要用于记录当前的Cue的Index并且,当我们点击按钮时能够动态的切换其数值,来变更将要播放的Cue Index从而更改和播放相关Cue。
为了能够通过界面进行Cue的切换,我们需要对下面的按钮进行点击事件的逻辑创建:
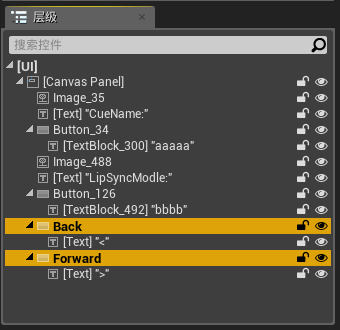

创建的逻辑如下:
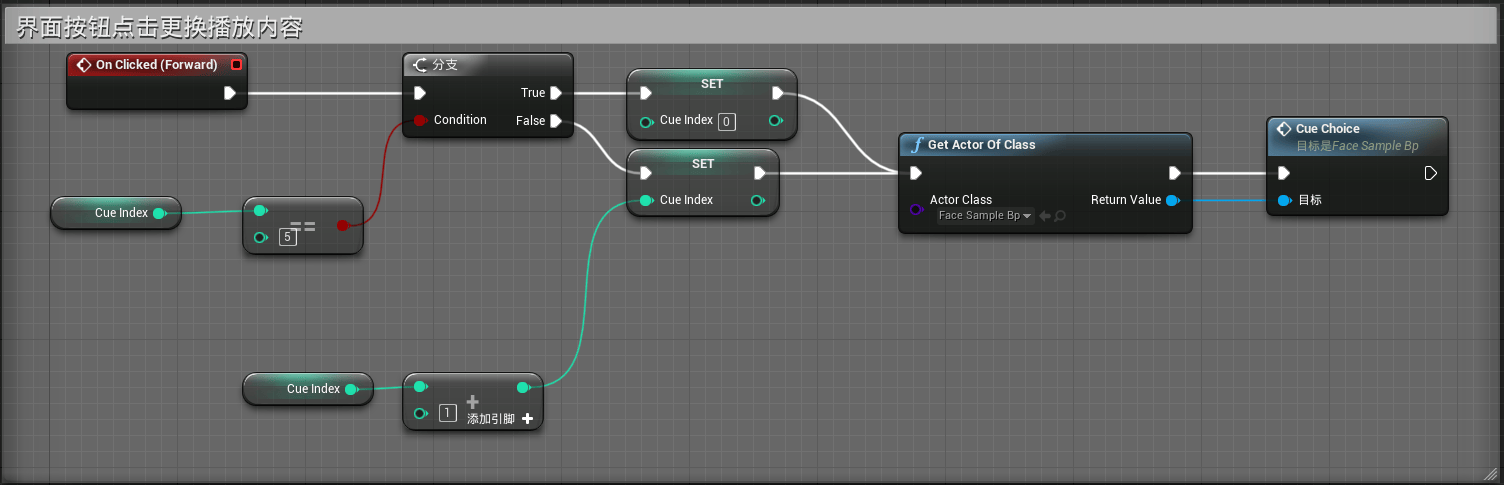
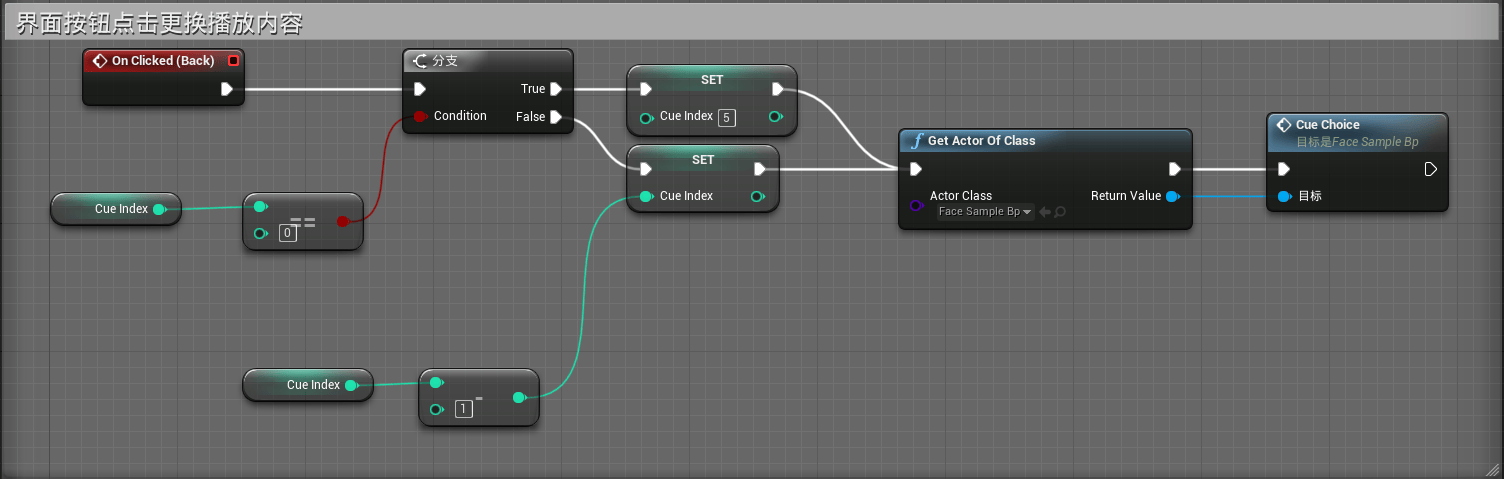
上图中显示通过CueIndex的值,当点击按钮时选择增加或减少1,当超过或小于某个值时回到正确的索引范围内,当然笔者这里使用的是具体的数字,更加常规的做法是需要在模型蓝图类中获取CueList的Length,将其值传入进行控制。
当点击按钮后,会执行CueChoice的自定事件,同时将相关的Cue Index传入模型蓝图类中用于选择CueList中的Cue内容,并进行播放。
如此一来就完成了我们的Cue的切换,我们可以实时的切换Cue,并实时的更改模式来测试我们创建的原型效果。
我们还可以再在模型蓝图中和UI控件蓝图中创建如下逻辑,使得单机按钮时进行当前Cue的再次播放,以此来方便观察同一个语音在不同的模式下口型表现效果:
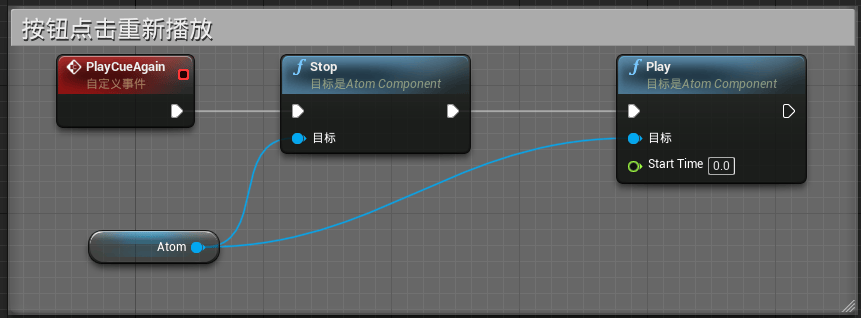
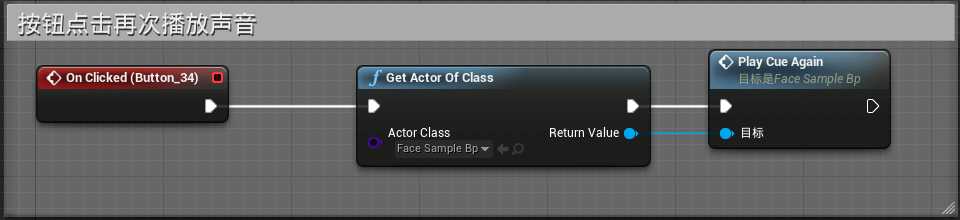
完成上述内容后,我们就能够完整的完成一套原型,该原型能够通过点击按钮切换口型分析模式,同样可以更改播放的Cue内容来测试同一模式下不同语种的口型效果以及同一语种下,不同模式的口型效果。
最终完成效果参考:
https://v.qq.com/x/page/l3045qfggh9.html
可以看到,在不同的模式下的表现效果不同,Volume形式下表现较差,高度宽度模式可以较好匹配语音,而音素混合量模式则表现更加。通过语音内容的分析,我们得到口型数据,从而驱动模型的变形参数使之与语音同步匹配。
这种方式下效果较好,且成本很低非常适合大量语音口型同步制作。
(5)·Unity应用
与Unreal中类似,我们通过导入资源文件,在Unity中创建相关Object,并添加相关代码,最终做出口型同步效果。同样我们也将制作支持界面按钮点击切换模式与切换播放的语音。
①·模型资源
当导入我们包含了变形参数的模型后,我们需要将其拖拽到场景中,并调节相关位置使之能够在摄像机中被看到。
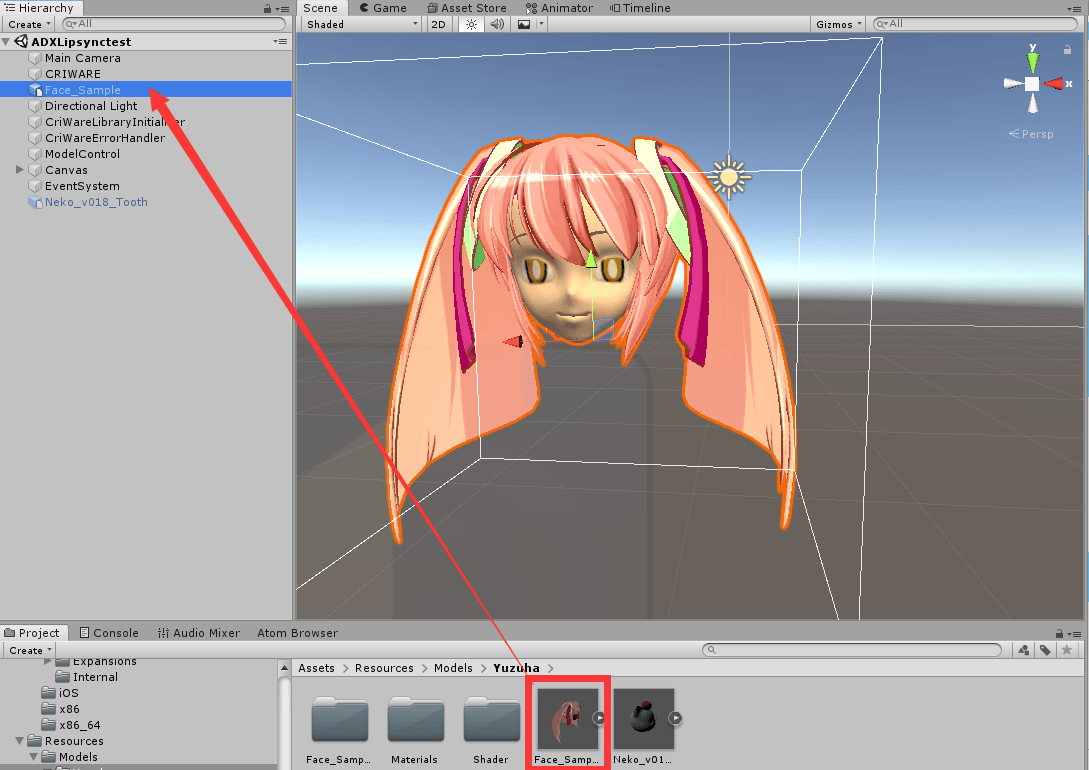
模型放在Hierarchy中以备后续调用。
②·界面按钮创建
我们希望能够在运行时实时调整口型的分析模式,且实时更换播放的语音内容,因此我们可以通过创建按钮来实现这些功能:
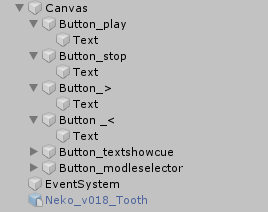
如上图,创建6个界面按钮,从上至下功能依次为:
- "Button_play":播放Cue(事件)按钮,当按下按钮时播放相关语音。
- "Button_stop":停止Cue(事件)按钮,当按下按钮时停止播放相关语音。
- "Button_>":切换Cue(事件)按钮,当按下按钮时将会切换播放的语音。
- "Button_<":切换Cue(事件)按钮,当按下按钮时将会切换播放的语音。
- "Button_textshowcue":显示Cue(事件)名称,当更换Cue时,显示文本跟随Cue名称变化。
- "Button_modleselector":显示当前口型模式,按下按钮时将会切换模式且按钮上文本将会跟随转变。
其中前四个按钮为功能性质按钮,按钮点击后会对应上述功能,但显示的文本不变,第五个单纯显示Cue名称,第六个是显示和功能性按钮,按下后将会对应功能且文本显示也将发声变化。
③·声音资源处理
准备好我们的模型和按钮后,我们需要处理声音资源,所有的声音素材都经过中间件ADX2进行打包后倒入到Unity中,此时我们创建一个空的Object于Hierarchy中,并重命名为CRIWARE,同时点击Add Component按钮,创建Cri Atom组件脚本:
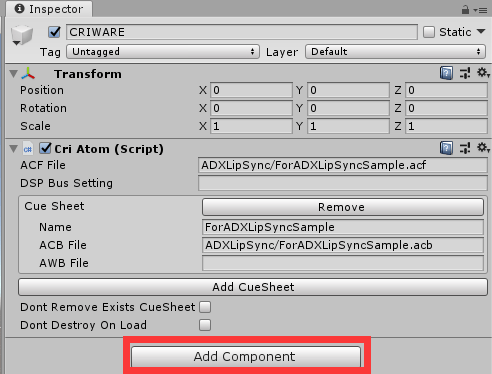
添加完成后,在Cri Atom中填写相关acf,acb以及awb文件路径,以备使用。
④·口型模式
在接下来的步骤中,我们将处理口型模式与模型变形参数,使之能够被我们正常的调用。
我们继续在Hierarchy中创建一个空的Object并命名为:ModelControl,而后在其上点击Add Component按钮添加脚本组件:"Cri Lips Shape For Atom Source":
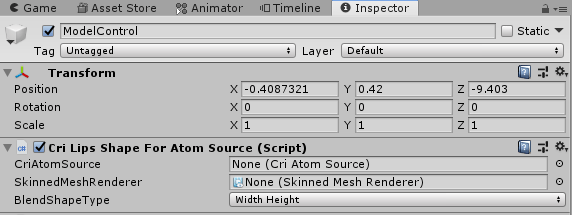
可以看到在该脚本中我们需要添加两个内容:Cri Atom Source以及SkinnedMeshRenderer。
Cri Atom Source我们稍后添加,首先将SkinnedMeshRenderer添加完成,我们在Hierarchy中选择之前的模型组件,将其拖拽到SkinnedMeshRenderer上完成添加:
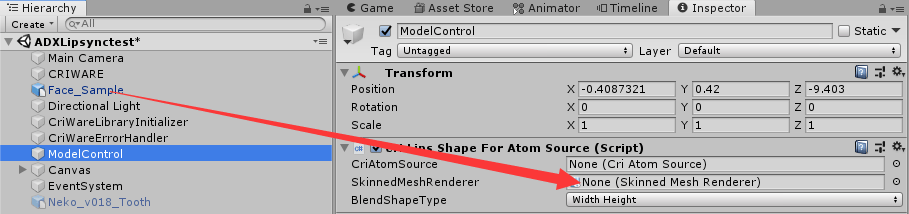
添加完成后将会出现下面的内容:
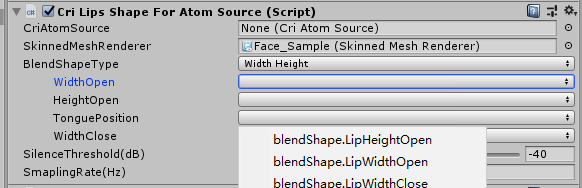
此时点击BlendShapeType就可以选择宽度高度模式还是音素混合量分析模式,而在其下方的内容中点击就可以选择 我们之前在模型中创建的变形参数名称。
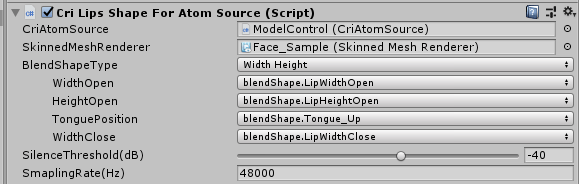
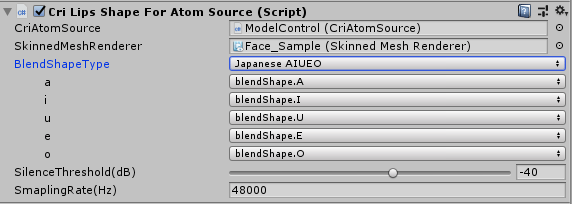
将我们创建好的模型变形数据依次填写完成,这样就完成了不同口型模式下各个音频分析的口型数据对应的模型变形参数的匹配。
我们再在ModelControl中通过Add Component添加一个Cri Atom Source组件,
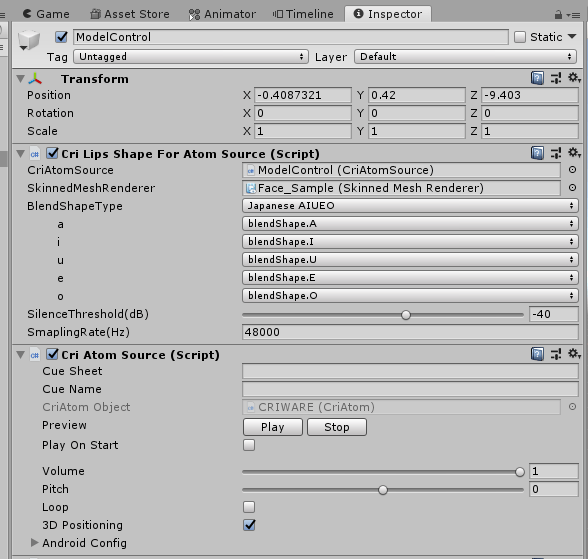
完成后,我们选择Hierarcgy中的ModelControl将其拖拽到之前创建的"Cri Lips Shape For Atom Source"脚本组件中的CriAtomSource中:
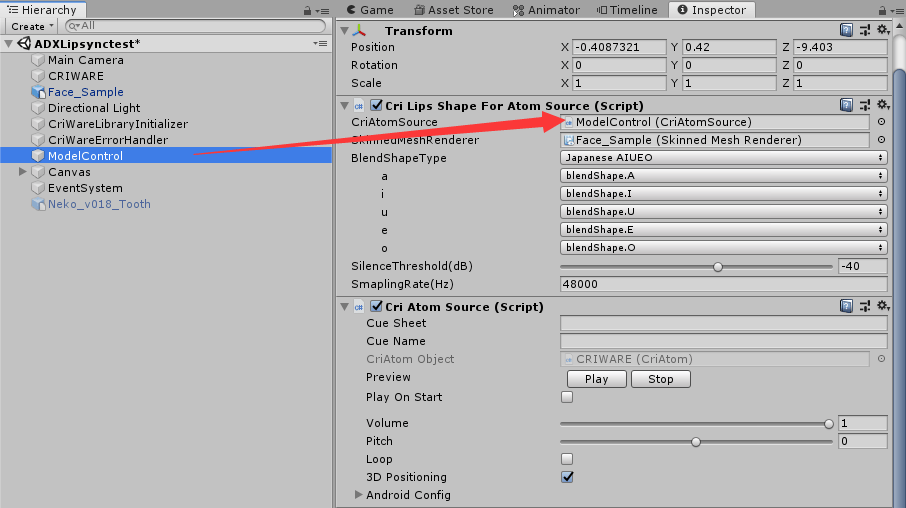
这样一来,我们"Cri Lips Shape For Atom Source"需要的相关信息就已经添加完成,下面需要进行脚本处理。
⑤·处理脚本
我们最终希望的效果是能够在运行过程中切换口型模式,同时也能切换播放的语音内容,而Play和Stop按钮也可以控制Cue的播放和停止,因此我们需要创建一个自定义脚本脚本内容如下:
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using UnityEngine.UI;
public class ADXLipsync : MonoBehaviour
{
#region
public CriAtomSource atomsource = null;
public string cueSheetName = "";
public CriLipsShapeForAtomSource shapeForAtomSource = null;
private CriAtomExAcb acb = null;
private CriAtomEx.CueInfo[] cueInfos;
private int selectedCueIndex = 0;
public Text textname;
public Text modelName;
#endregion
// 初始化相关信息/显示当前口型模式/设置当前口型模式
#region
void Start()
{
if (!string.IsNullOrEmpty(cueSheetName))
{
acb = CriAtom.GetAcb(cueSheetName);
cueInfos = acb.GetCueInfoList();
modelName.text = "JapaneseAIUEO";
shapeForAtomSource.blendShapeType = CriLipsShape.BlendShapeType.JapaneseAIUEO;
}
}
// 更新显示语音名称
void Update()
{
textname.text = cueInfos[selectedCueIndex].name;
}
// play按钮点击播放音频
public void PlayCue()
{
atomsource.player.SetCue(acb, cueInfos[selectedCueIndex].name);
if (atomsource.status == CriAtomSource.Status.Playing)
{
atomsource.player.Stop();
}
atomsource.player.Start();
}
// stop按钮点击停止音频
public void StopCue()
{
atomsource.player.Stop();
}
// 修改播放音频的index
public void SetSelectedCueIndexIncrease()
{
if (selectedCueIndex >= cueInfos.Length - 1)
{
selectedCueIndex = 0;
}
else
{
selectedCueIndex++;
}
}
public void SetSlectedCueIndexDecrease()
{
if (selectedCueIndex <= 0)
{
selectedCueIndex = cueInfos.Length - 1;
}
else
{
selectedCueIndex--;
}
}
// 更改口型模式
public void changeModle()
{
switch (shapeForAtomSource.blendShapeType)
{
case CriLipsShape.BlendShapeType.WidthHeight:
shapeForAtomSource.blendShapeType = CriLipsShape.BlendShapeType.JapaneseAIUEO;
SetBlendShapeWidthHeightAtSilence(shapeForAtomSource);
modelName.text = "JapaneseAIUEO";
break;
case CriLipsShape.BlendShapeType.JapaneseAIUEO:
shapeForAtomSource.blendShapeType = CriLipsShape.BlendShapeType.WidthHeight;
setSetBlendShapeJapaneseAIUEOAtSilence(shapeForAtomSource);
modelName.text = "WidthHeight";
break;
default:
break;
}
}
// 模式切换还原数据
/// <summary>
/// 还原宽度高度数据
/// </summary>
private void SetBlendShapeWidthHeightAtSilence(CriLipsShapeForAtomSource lipsShapeForAtomSurce)
{
BlendShapeWeighString(lipsShapeForAtomSurce.skinnedMeshRenderer, lipsShapeForAtomSurce.nameMapping.WidthHeightName.lipHeightOpenName, 0.0f);
BlendShapeWeighString(lipsShapeForAtomSurce.skinnedMeshRenderer, lipsShapeForAtomSurce.nameMapping.WidthHeightName.lipWidthCloseName, 0.0f);
BlendShapeWeighString(lipsShapeForAtomSurce.skinnedMeshRenderer, lipsShapeForAtomSurce.nameMapping.WidthHeightName.lipWidthOpenName, 0.0f);
BlendShapeWeighString(lipsShapeForAtomSurce.skinnedMeshRenderer, lipsShapeForAtomSurce.nameMapping.WidthHeightName.tonguePosition, 0.0f);
}
/// <summary>
/// 还原元音数据
/// </summary>
private void setSetBlendShapeJapaneseAIUEOAtSilence(CriLipsShapeForAtomSource lipsShapeForAtomSurce)
{
BlendShapeWeighString(lipsShapeForAtomSurce.skinnedMeshRenderer, lipsShapeForAtomSurce.nameMapping.japaneseAIUEOName.a, 0.0f);
BlendShapeWeighString(lipsShapeForAtomSurce.skinnedMeshRenderer, lipsShapeForAtomSurce.nameMapping.japaneseAIUEOName.e, 0.0f);
BlendShapeWeighString(lipsShapeForAtomSurce.skinnedMeshRenderer, lipsShapeForAtomSurce.nameMapping.japaneseAIUEOName.i, 0.0f);
BlendShapeWeighString(lipsShapeForAtomSurce.skinnedMeshRenderer, lipsShapeForAtomSurce.nameMapping.japaneseAIUEOName.o, 0.0f);
BlendShapeWeighString(lipsShapeForAtomSurce.skinnedMeshRenderer, lipsShapeForAtomSurce.nameMapping.japaneseAIUEOName.u, 0.0f);
}
private void BlendShapeWeighString(SkinnedMeshRenderer skinnedMeshRenderer,string blendShapeName,float weight)
{
if (string.IsNullOrEmpty(blendShapeName))
{
return;
}
int index = skinnedMeshRenderer.sharedMesh.GetBlendShapeIndex(blendShapeName);
if (index < 0)
{
return;
}
skinnedMeshRenderer.SetBlendShapeWeight(index, weight);
}
#endregion
}
在上面的脚本中我们主要进行了以下内容:
- 首先定义了acb,acb是声音的资源文件,其中存储了需要播放的所有Cue内容。
- 同时通过acb获取了其中的cue内容,将其显示在界面上。
- 创建了自定义的PlayCue,StopCue,SetSelectedCueIndexIncrease以及SetSlectedCueIndexDecrease方法,分别用于播放Cue,停止Cue以及选择Cue内容,使用的是从acb中获取的CueIndex。
- 创建了自定义的changeModle方法,用于点击按钮时能够切换口型模式(宽度高度模式以及音素混合量分析模式)。
- 在changeModle方法中使用了SetBlendShapeWidthHeightAtSilence和setSetBlendShapeJapaneseAIUEOAtSilence方法,这两个方法主要用于在切换模式时将相关的数据还原,使得口型变回基础状态。
完成脚本内容后,我们需要将创建的脚本方法与按钮的点击以及各个文本显示相连接:
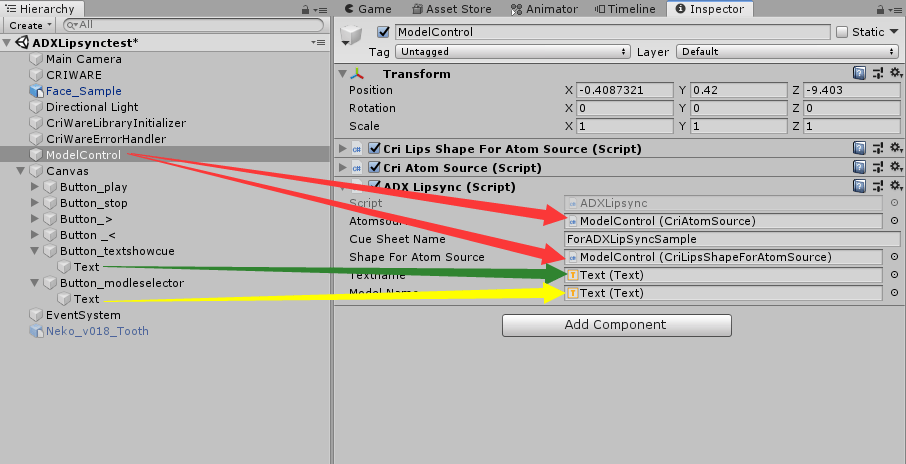





如此一来我们的脚本内容和按钮就可以进行使用了,运行场景来测试一下效果吧。
https://v.qq.com/x/page/k3045g4wtqe.html
ADX LipSync使用简便,又能够和音频中间件ADX2联合使用,完美解决了当想使用音频进行口型实时分析时,不能将音频进入音频中间件管理的问题。
同时分析的效果也相对较好,快速的帮助游戏项目完成非常好的口型效果表现。