手游特效太多怎么办?这里有一份性能优化方案可参考
发布时间:2019-09-27
本期分享嘉宾:KM,图形图像优化渲染方面专家。
在 ACT 游戏中华丽的特效是不可或缺的部份,但渲染这类半透明特效时往往带来的性能上的开销,特别在最高画质打开 HDR 及 MSAA 后情况更为严重。本篇文章将从移动端 GPU 的运作特性分析半透明特效在高画质的设定下造成性能问题的原因,并分享一个在 UE4 中实现的优化方案和结果。
移动端GPU运作特性
与桌上/主机 GPU 常见的 IMR (Immediate-Mode Rendering) 不同,现时市场上通用的移动端 GPU (例如 Adreno / Mali / PowerVR 等)都采用了 TBR(Tile Based Rendering) 的方案来节省数据传输的带宽;借此减少访问片外内存(Off-chip / External Memory 一个在移动平台上十分消耗电量和耗时的操作) 的次数。
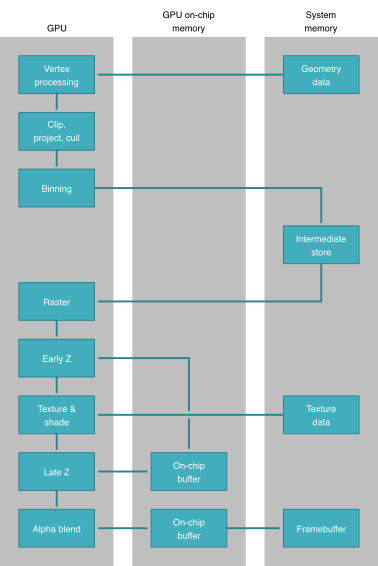
尽管每个硬件厂商在实现 TBR 的细节上有所不同,但运作原理都大致如下:[ 1 ]
首先,GPU 的 Tiler 会将画面分成一个个二维的 Tile (矩形区块)。模型的顶点经过 Vertex Shader / Clipping / Back Face Culling 以后会变成一个个屏幕空间的三角形,这些三角形会被缓存在一个 Triangle Cache 里面。假如某三角形需要在某个 Tile 里面绘制,那该 Tile 的 Triangle List 中存一个索引;以上步骤称为 Binning。
生成的 Triangle Cache 与 Triangle List 等数据会保存在 System Memory 中的 Intermediate store 内。
当一帧里所有的渲染命令都经执行完 Vertex Shader 并生成 Triangle List 后,GPU会把逐个 Tile 的 Triangle List 从 System Memory 传回 GPU 内并执行 Raster / Pixel Shader / Blending 等运算。[ 2 ]
对 GPU 的性能影响
HDR / MSAA
GPU 的 On-Chip Memory有非常高的读写速度,能大大提升MSAA/Alpha 混合的效率;但由于成本昂贵,因此 On-Chip Memory 的空间非常有限。例如从 Google 开源的 Andriod 驱动代码中可以得知,即使是旗舰级的 Adreno 630 亦只有 1 MiB 的 GMEM (即 Adreno 系列的 GPU On-Chip Memory)。[ 3 ]
由于打开 HDR 与 MSAA 需要更多空间来保存渲染结果,GPU 只能够透过缩小 Tile 的尺寸来乎合 On-Chip Memory 的固定大小。进行渲染的 Tile 数量会因此而增加。
换言之,从 System Memory 传送 Raster 数据到 GPU / 把渲染结果从 GPU 传回 Framebuffer 的次数会增加,为带宽造成压力及延迟 (Latency)。[ 4 ]
例子:假如GPU On-Chip Memory 大小为 1MB 同样以1920 x 1080 的分辨率 16-bit Depth 进行渲染的情况下,使用 LDR (RGBA) 以及没有 MSAA,Framebuffer 约需要:
· (1 + 1 + 1 + 1 + 2) Bytes 1 1920 * 1080 = 12441600 Bytes = 11.87MB
· 即需要拆分为 ~12个 Tile 来进行渲染
而使用 FP16 HDR 以及打开 4x MSAA Framebuffer 约需要:
· (2 + 2 + 2 + 2 + 2) Bytes 4 1920 * 1080 = 82944000 Bytes = 79.10MB
· 即需要拆分为 ~80个 Tile 来进行渲染
因此 HDR + 4x MSAA 会比 LDR 的多消耗 6 倍带宽。
Alpha 混合
即使 Alpha 混合是在高速的 On-Chip Memory 内进行,但是带 Alpha 混合的像素与像素之间不能启用早期 Early Z 优化,因此 Overdraw 的像素会对性能造成一定影响。
此外,移动端 GPU 的 Output Merger (或者 ROP) 进行定点数(UNORM) 的 Alpha 混合会比浮点数 (FP16) 有更佳的性能,因为一般的移动端 GPU Output Merger 都是模拟浮点数的混合。与此同时,移动端 GPU 在进行 MSAA 的浮点数 Alpha 混合时是需要逐个样本计算混合。即是说 4x MSAA 的 FP16 Alpha 混合每个 Fragment 便需要进行 4 遍 Alpha 混合计算。[ 5 ]
UE4 的移动端渲染管线
了解到移动端 GPU 的 HDR 及 MSAA 特性后,我们再分析一下 UE4 在移动端的渲染管线。
首先我们使用 RenderDoc 抓一帧的数据。
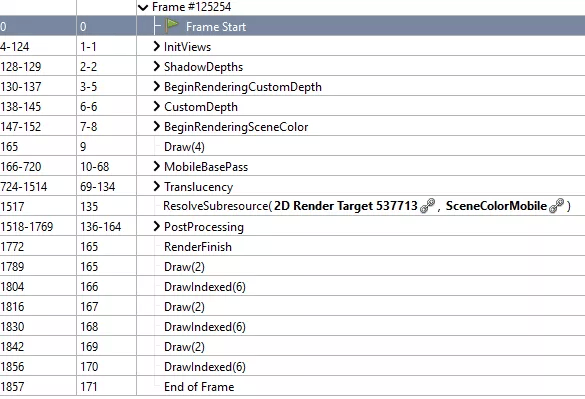
我们可以观察到 UE4 是直接以 FP16 + MSAA 的 SceneColorMobile RT (Render Target) 来渲染所有带 Translucency 的物件 (粒子系统/半透特效)。
之后会把 FP16 + MSAA 的 SceneColorMobile RT 进行 Resolve, 并运行后处理效果(此时只有 HDR ,不带 MSAA)。最后把后处理结果拷贝到屏幕的 Back Buffer 上并渲染 UI / HUD 等(这阶段都不带 HDR 与 MSAA)。
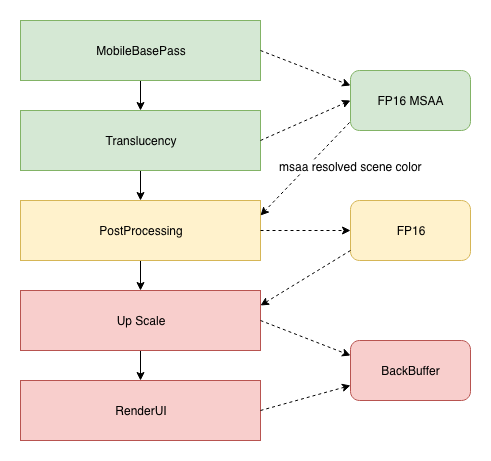
因此在一个放置 ~70个 Translucency Drawcall 的场景中,Draw Time 由 ~14 ms (不带 HDR / MSAA) 上升到 ~20 ms (带 HDR & MSAA)。
优化方案
MSAA 的特性
由于 MSAA 的抗锯齿效果是针对三角形的边沿部分而设计,对使用贴图定义透明度的特效基本上起不了什么作用。
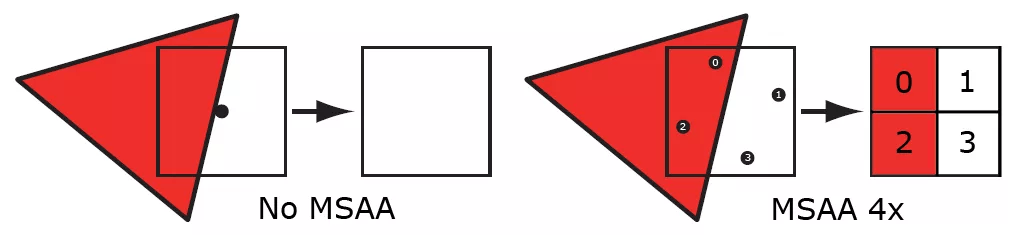
[ 6 ]
所以优化思路就是把半透明的特效先渲染到另一个没有带 MSAA 的 Render Target (RT) 内,之后再以后处理的方式混合到场景内。但这衍生另一个问题,如何在另一个 RT 渲染半透特效时使用现有场景的深度 (Z-Buffer) 来作 Depth-Test 呢?
移动端 MSAA
在桌上 GPU 我们可以把带 MSAA 的 Z-Buffer Resolve 到另一个相同尺寸但不带MSAA 的 Buffer 中,但移动端 GPU 一般都不带这功能。
在移动端 GPU,MSAA 一般是先把 MSAA 样本先暂存在 On-Chip Memory 之后马上进行 Resolve,最后在整个 Tile 完成渲染时把结果传回 System Memory 的 RT 内。因此移动端的 Color RT 都不会带 MSAA 样本。
针对以上特性,UE4 的移动端渲染管线在打开 HDR (FP16) 支持后会把已线性化的场景深度 (Linear SceneDepth) 直接保存到 Color RT 的 Alpha 通道内,以便在后处理效果(例如: Depth of Field / Sun Shaft)中能够访问场景深度。
因此在我们的方案中,是把 Color RT 的 Alpha 通道改为保存未线性化的深度(UE4 是 Reversed Z),在渲染半透特效之前把 SceneDepth 以后处理的 Shader 复制到半透 RT 的 Z-Buffer 内。
跨 RT 的 Alpha 混合
另一个需要解决的问题是如何把半透 RT 的 Alpha 混合结果再次混合到场景 RT 内。
假如我们需要混合三个输出的像素 s1, s2, s3, 其 Alpha 值为 a1, a2, a3,当前 Framebuffer 的颜色是 d0 ;混合结果为 d1, d2, d3:
d1 = d0 * (1 - a1) + s1 * a1;
d2 = d1 * (1 - a2) + s2 * a2;
d3 = d2 * (1 - a3) + s3 * a3;
把以上公式分别以上一步代入:
d2 = [d0 * (1 - a1) * (1 - a2)] + [s1 * a1 * (1 - a2) + s2 * a2];
d3 = [d0 * (1 - a1) * (1 - a2) * (1 - a3)] + [s1 * a1 * (1 - a2) + s2 * a2] * (1 - a3) + s3 * a3;
从 d3 的公式我们可以观察到 d3 是由两个部分相加而成:
· [d0 * (1 - a1) * (1 - a2) * (1 - a3)]
· [s1 * a1 * (1 - a2) + s2 * a2] * (1 - a3) + s3 * a3
因此我们以半透 RT 的
· Alpha 通道保存 fx.a = (1 - a1) * (1 - a2) * (1 - a3)
· RGB 通道则保存 fx.rgb = [s1 * a1 * (1 - a2) + s2 * a2] * (1 - a3) + s3 * a3
· 对应渲染特效的Blending Factors 则设为:
· AlphaBlendEnable = true;
· SrcBlend = SrcAlpha;
· DestBlend = InvSrcAlpha;
· SeparateAlphaBlendEnable = true;
· SrcBlendAlpha = Zero;
· DestBlendAlpha = InvSrcAlpha;
最后便可以透过 d0 * fx.a + fx.rgb; 把特效混合回场景的RT 内。[ 7 ]
其他细节
·
· 由于在移动端 GPU 的浮点数 Alpha 混合比较慢 (在 S820 上以 1280 x 720
结果
优化后的渲染管线
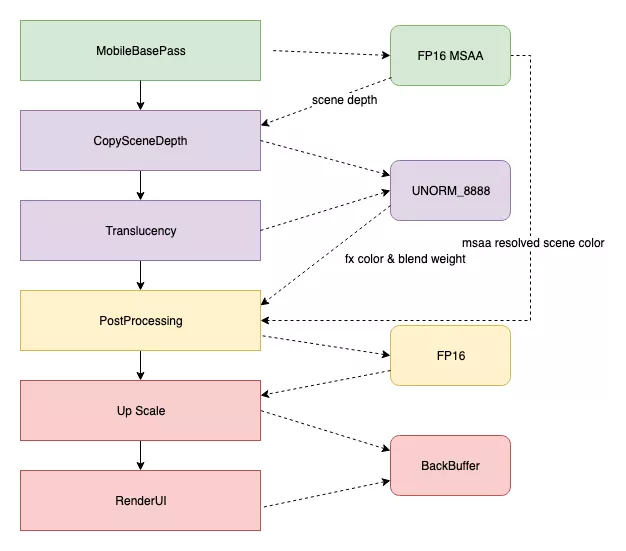
性能
在 Snapdragon 820 (Adreno 530) 的手机中录得以下结果:

此外,我们发现在一些更低阶的移动 GPU (例如 Snapdragon 650 的 Adreno 510 )上,使用半透 RT 的优化效果会更显著。
总结
本文分析了移动端 GPU的运作特性,以及半透特效为何在打开 HDR 及 MSAA 之后会造成性能问题的原因;亦建议了一个在虚幻4引擎中的优化方案。
由于现时的方案是把所有的半透 Draw Call 全都渲染到另一个 RT,在使用 1/4 面积的情况下一些非特效的半透物件(例如 Billboard 树,植皮… 等)会显示得比较模糊。因此这类物件建议在 Editor 中标注为以 Alpha to Converage 的方式直接渲染到场景 RT 里。
另外,在现时方案中,当使用一半大小的半透 RT 时会有场景像素“漏” (Leaking) 到特效里的情况,这可以透过在复制Scene Depth 到半透 RT 的 Z-Buffer 时加上采邻近 2x2 的 Scene Depth 的最大值来解决。但我们的项目因为性能的考虑没有加入这个功能。
参考
· [1] 三星:移动端 GPU Tiler 运作原理
· [2] 三星:移动端 GPU 架构简介
· [3] Google 开源的 Adreno 驱动: 第 373 行
· [4] Occlus Rift Adreno 的开发注意事项
· [5] ARM:registered: Mali:tm: Application Developer Best Practices: JUST14
· [6] 战神系列(God of War) Lead Graphics Programmer 关于 MSAA 运作原理的文章
· [7] GPU Gems 3 中关于 Off-screen Particles 的文章
· [8] CSDN - Adreno GPU Architecture
