IOC两种实现方法详解
上篇内容中简单给大家介绍了下IOC的概念和实现思路,这篇就借助方法的讲述让大家掌握IOC。IOC总结一句话就是框架帮开发者生成对象,以达到解耦的目的。
上次说到,IOC的两种实现思路:
1.反射;
2.new 对象。
比如现在有两个类,Computer 和 Host类。
Computer.java
public class Computer {
private Host host;
public Computer(Host host){
this.host = host;
}
public Host getHost(){
return this.host;
}
}
Host.java
public class Host {
private String name;
public Host(){ }
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
Computer 强依赖Host 的一个对象(Host 是Computer的构造入参)。为了简单演示,Host没有再深一层的依赖。
现在要生成Computer 类的对象(有一个依赖)和Host类的对象(没有依赖)。
反射的思路
反射需要类信息,可以用一个xml文件来描述。
Container.xml
<?xml version="1.0" encoding="utf-8" ?>
<container>
<bean name="computerName"
path="com.example.yueshaojun.ioc.bean.Computer">
<dependence
name="hostName"
path="com.example.yueshaojun.ioc.bean.Host" />
</bean>
</container>
这个xml的结构也很简单,用来描述Computer和Host的依赖关系,和java代码的依赖关系对应。name 表示名字,path表示类所在的路径。这里的标签全是自己定义的。
有了这个xml后,就要开始解析它了。为了Android项目的方便,放在了Asset目录下,并且使用了Android中的Dom解析。当然,使用什么工具并不是重点,搞清楚解析的逻辑过程才是重点,代码如下:
Parser.java
public class Parser {
public static void parse(Context context) {
try {
InputStream inputStream = context.getResources().getAssets().open("container.xml");
DocumentBuilderFactory factory = DocumentBuilderFactory
.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(inputStream);
// 获取根节点
Element root = document.getDocumentElement();
NodeList nodeList = root.getChildNodes();
for (int i = 0; i < nodeList.getLength(); i++) {
Node child = nodeList.item(i);
Log.i("ysj", "node local name" + child.getNodeName());
if ("bean".equals(child.getNodeName())) {
String keyName = ((Element) child).getAttribute("name");
String path = ((Element) child).getAttribute("path");
Class childClass = Class.forName(path);
Constructor[] constructor = childClass.getConstructors();
for (int j = 0; j < constructor.length; j++) {
Class<?>[] paramTypes = constructor[j].getParameterTypes();
Object[] paramObjectList = new Object[paramTypes.length];
for (int f = 0; f < paramTypes.length; f++) {
Class paramClass = paramTypes[f];
if (Container.get(paramClass) == null) {
NodeList childChildNodes = child.getChildNodes();
for (int k = 0; k < childChildNodes.getLength(); k++) {
Node childChild = childChildNodes.item(k);
if ("dependence".equals(childChild.getNodeName())) {
String childKeyName = ((Element) childChild).getAttribute("name");
String childPath = ((Element) childChild).getAttribute("path");
Class childChildClass = Class.forName(childPath);
Object childChildValue = childChildClass.newInstance();
paramObjectList[f] = childChildValue;
Container.add(childChildClass, childChildValue);
}
}
} else {
paramObjectList[f] = Container.get(paramClass);
}
}
Object childValue = constructor[j].newInstance(paramObjectList);
Container.add(childClass, childValue);
break;
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
看完这段代码,可能很多人都觉得臃肿,嵌入了太多的for 循环和if else,代码忽略到,注意下思路:
1、解析到bean 标签 ,通过path拿到全路径;
2、检查这个类(Computer)的构造列表,检查它有没有依赖(dependence标签);
3、如果有依赖,检查Container中是否需要的实例,如果有直接到5;假如依赖的类(Host)没有强依赖(空构造入参),那么反射生成Host的对象,并把它加到Container中;
4、如果有依赖,假如依赖的类(Host)还有强依赖(有其他构造入参),那么按照2的逻辑继续查找,直到找到没有强依赖的对象,按照3的逻辑走。
5、Host(需要依赖的类)的对象反射出来后,再作为Computer(需要依赖的类)的构造器Constructor 的入参,生成Computer对象,并把它加到Container中。
Container.java:
public class Container {
private static HashMap<Class<?>,Object> beanContainer = new HashMap<>();
public static void add(Class<?> key,Object value){
beanContainer.put(key,value);
}
public static Object get(Class<?> key){
return beanContainer.get(key);
}
}
它只是持有了全局静态的一个hashMap,这个hashmap为了方便我只是用class做key。(当然也可以用xml中配置的name属性来作为key,我只是偷懒图方便)。再配两个图用于理解:

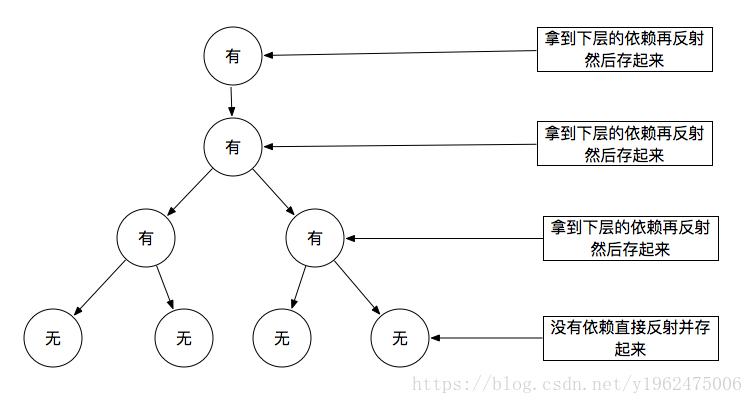
对于构造入参深度遍历,找到最子叶子节点,生成对象,再逐层向上递归。直到所有节点都生成对象。
这个解析之后Container中就持有了Computer和Host两个类的对象。
再次强调事实上可能并不是这么写的,实际上框架做的事会多得多。但是我的目的只是生成一个对象,所以到了解析host之后就并没有递归的向下解析,但是这并不妨碍理解这个过程。
因为生成的对象可能应用启动后就使用,把解析过程放到了Application 中:
public class AppContext extends Application {
@Override
public void onCreate() {
super.onCreate();
Parser.parse(this);
}
}
后面只需要
(Computer) Container.get(Computer.class)
就可以拿到Computer的实例,当然,Host实例也这么拿。
xml只是个例子,它代表了持久化(写在文件里)类信息的一种方式,例如properties、json文件等。
new 对象
看完上面的东西,做Android的同学要暴走了:xml(或者其他文件)在android中并不安全,反射性能又差,静态的全局HashMap又会导致内存泄漏,application中解析又会造成启动慢。这玩意能用吗?当然不能用了……于是有了第二种。既然想让框架生成一个对象,框架帮你new呗……这个就要借助编译时注解了。编译时注解怎么用这里不去说,只要知道编译完后,生成如下的一个类:
Injector.java
class Injector {
public static void bindMember(final MainActivity activity) {
activity.host = new Host();
}
}
那么运行时只要调用 Injector.bindMember(mainActivity); activity.host = new Host();这段代码就会执行,这个Host的对象自然也就出来了。那Computer的对象呢?来来来,往上翻,看官请看看第二张图,有了Host的对象,还new 不出Computer吗?看起来是不是很简单?当然还是那句话,为了只关注怎么让框架生成一个对象,只是做简单的演示。实际上要真正使用,还要有很多的细节。不过万变不离其宗,搞清楚核心了,其他自然就容易了。
总结
反射的方式是在启动的时候生成对象,用HashMap持有
优点:应用一启动,所有配置的类的对象都会生成,生命周期 = 应用生命周期;
缺点:适合服务端,不适合移动端。xml放在app不安全、解析会导致启动慢、反射耗性能、静态HashMap会内存泄漏。
new 对象的方式是在编译时生成一行“new XXX()“,运行时调用。
优点:编译时生成代码,使用时才生成对象,资源代价小。
缺点:对框架的要求高(生成代码很繁琐,想要更易用也需要做很多工作)。
不管哪种方式,IOC的都是通过一个映射关系生成对象,而上述两者的本质是:
xml是将这种映射关系维系在了静态文件中,new 对象的方式是将这种映射关系维系在了注解和被注解的对象(本质上是class 和 method这种调用关系)中,只有在运行时才会知道要生成的是谁。
更多细节,可以看代码:https://github.com/yueshaojun/ioc.git
分析:这两种方式大家可以选择最适合自己项目的方式,只需要注意两者的区别于优缺点即可。