性能优化,永无止境---CPU篇
性能优化是游戏项目开发过程中一个永恒的话题。玩家的需求和项目的要求永远在不停增长,同屏人数、屏幕特效和场景复杂度永远在向着“榨干”硬件的趋势逼近。所以,无论硬件设备发展到何种程度,无论研发团队有多么丰富的经验积累,性能优化永远是一个非常棘手而又无法绕开的问题。
就当前游戏而言,性能优化主要是围着CPU、GPU和内存三大方面进行。下面,我们就这三方面来说说当前移动游戏项目中存在的普遍问题和相应的解决方案。
CPU方面
就目前的Unity移动游戏而言,CPU方面的性能开销主要可归结为两大类:引擎模块性能开销和自身代码性能开销。其中,引擎模块中又可细致划分为渲染模块、动画模块、物理模块、UI模块、粒子系统、加载模块和GC调用等等。正因如此,我们在UWA测评报告中,就这些模块进行详细的性能分析,以方便大家快速定位项目的性能瓶颈,同时,根据我们的分析和建议对问题进行迅速排查和解决。
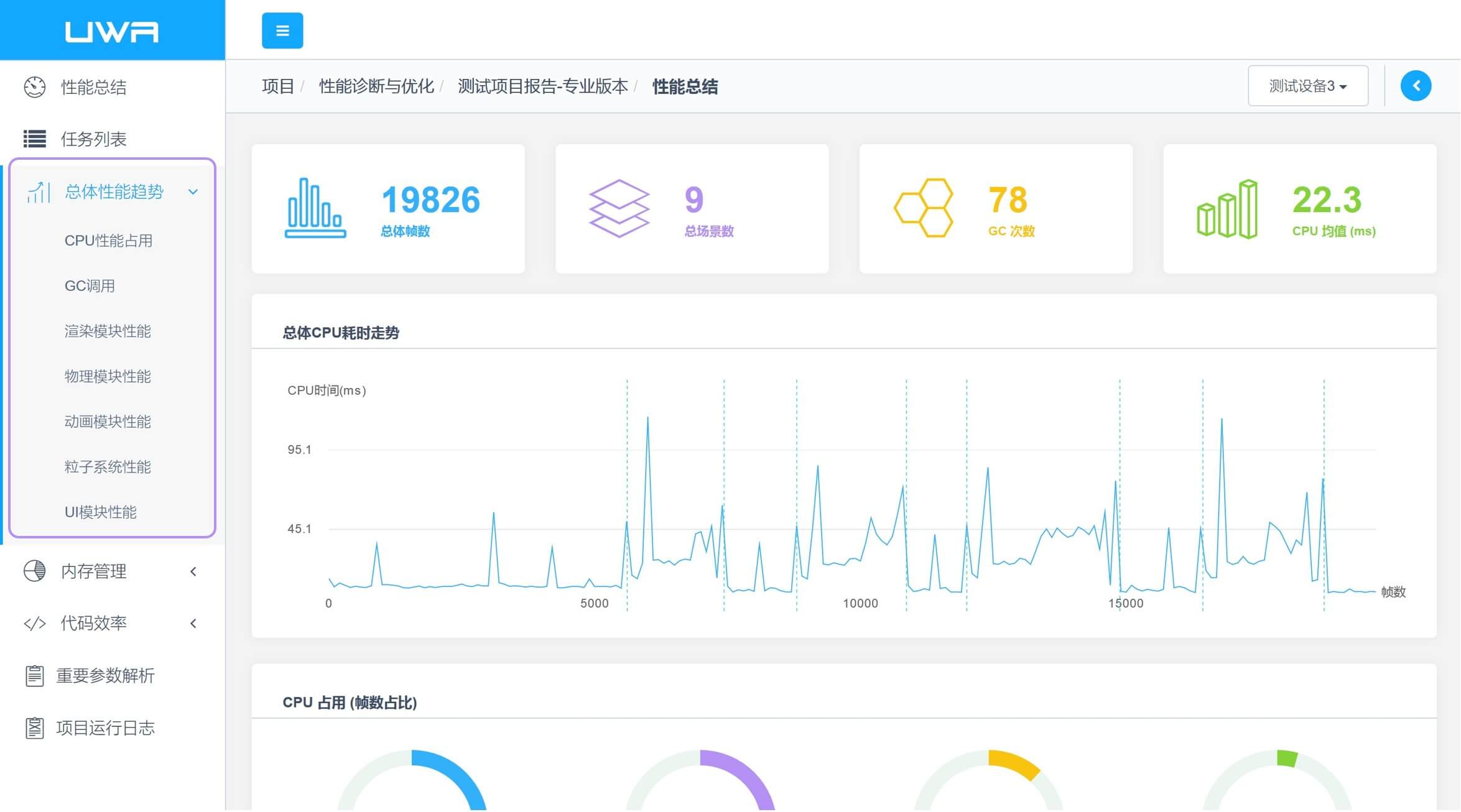
通过大量的性能测评数据,我们发现渲染模块、UI模块和加载模块,往往占据了游戏CPU性能开销的Top3。
一、渲染模块
渲染模块可以说是任何游戏中最为消耗CPU性能的引擎模块,因为几乎所有的游戏都离不开场景、物体和特效的渲染。对于渲染模块的优化,主要从以下两个方面入手:
(1)降低Draw Call
Draw Call是渲染模块优化方面的重中之重,一般来说,Draw Call越高,则渲染模块的CPU开销越大。究其原因,要从底层Driver和GPU的渲染流程讲起,限于篇幅我们不在这里做过多的介绍。有兴趣的朋友可以查看这里,或者自行Google相关的技术文献。
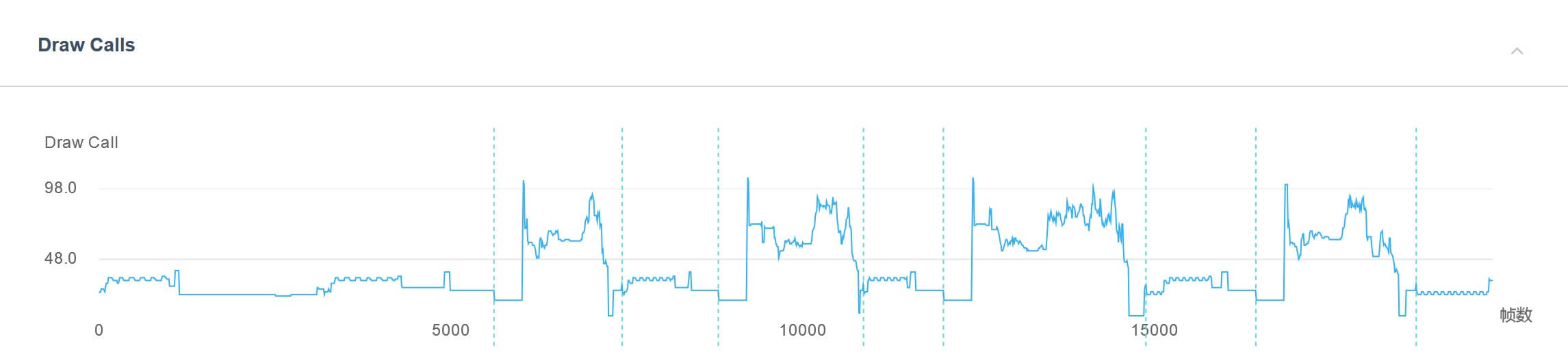
降低Draw Call的方法则主要是减少所渲染物体的材质种类,并通过Draw Call Batching来减少其数量。Unity文档对于Draw Call Batching的原理和注意事项有非常详细的讲解,感兴趣的朋友可以直接查看 Unity官方文档。
但是,需要注意的是,游戏性能并非Draw Call越小越好。这是因为,决定渲染模块性能的除了Draw Call之外,还有用于传输渲染数据的总线带宽。当我们使用Draw Call Batching将同种材质的网格模型拼合在一起时,可能会造成同一时间需要传输的数据(Texture、VB/IB等)大大增加,以至于造成带宽“堵塞”,在资源无法及时传输过去的情况下,GPU只能等待,从而反倒降低了游戏的运行帧率。
Draw Call和总线带宽是天平的两端,我们需要做的是尽可能维持天平的平衡,任何一边过高或过低,对性能来说都是无益的。
(2)简化资源
简化资源是非常行之有效的优化手段。在大量的移动游戏中,其渲染资源其实是“过量”的,过量的网格资源、不合规的纹理资源等等。所以,我们在UWA测评报告中对资源的使用进行了详细的展示(每帧渲染的三角形面片数、网格和纹理资源的具体使用情况等),以帮助大家快速查找和完善存在问题的资源。

关于渲染模块在CPU方面的优化方法还有很多,比如LOD、Occlusion Culling和Culling Distance等等。我们会在后续的渲染模块技术专题中进行更为详细的讲解,敬请期待。
二、UI模块
UI模块同样也是几乎所有的游戏项目中必备的模块。一个性能优异的UI模块可以将游戏的用户体验再抬高一个档次。在目前国内的大量项目中,NGUI作为UI解决方案的占比仍然非常高。所以,UWA测评报告对NGUI的性能分析进行了极大的支持,我们会根据用户所使用的UI解决方案(UGUI或NGUI)的不同提供不同的性能分析和优化建议。
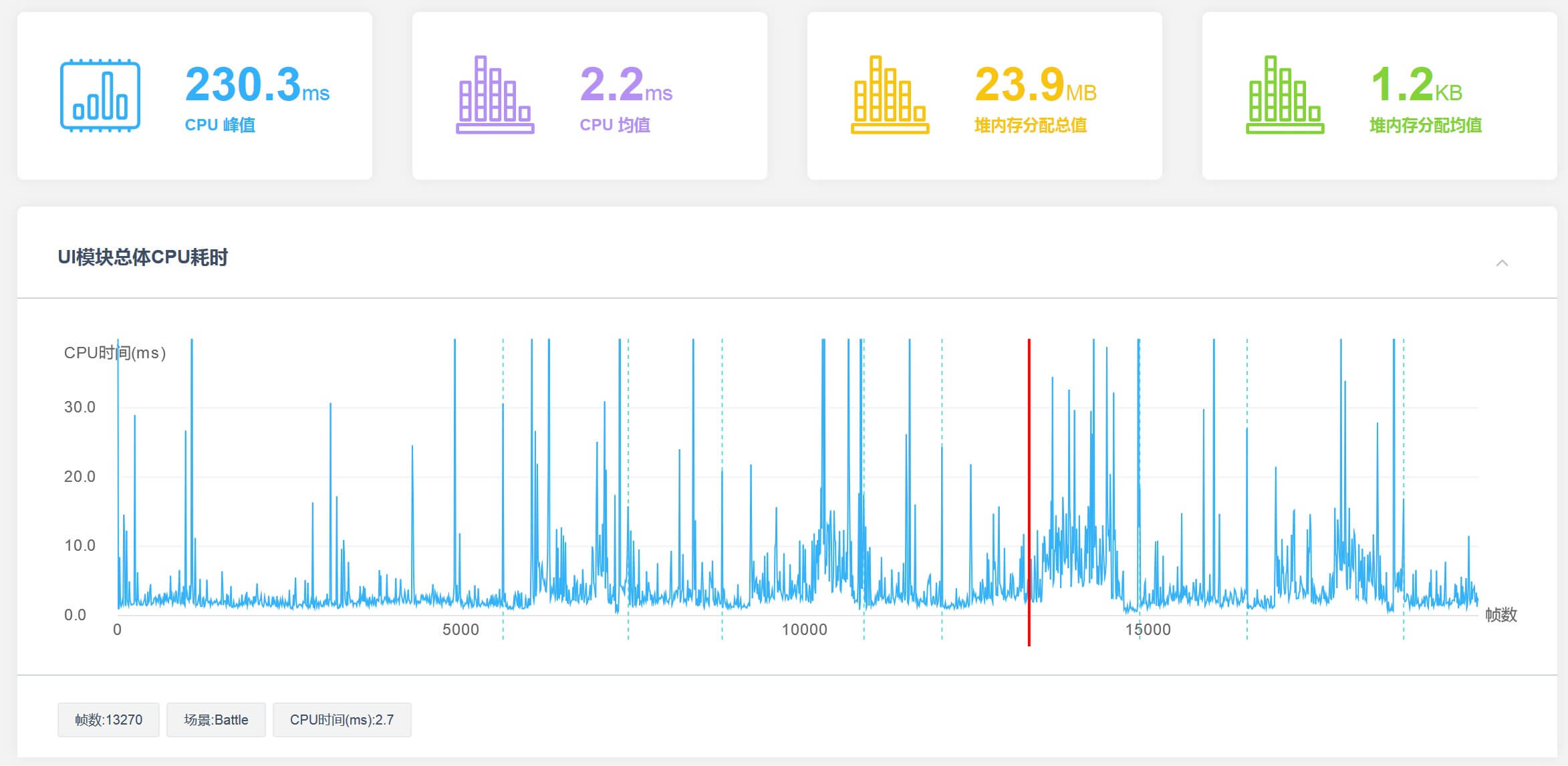
在NGUI的优化方面,UIPanel.LateUpdate为性能优化的重中之重,它是NGUI中CPU开销最大的函数,没有之一。UI模块制作的难点并不在于其表现上,因为UI界面的表现力是由设计师来决定的,但两套表现完全一致的UI系统,其底层的性能开销则可能千差万别。如何让UI系统使用尽可能小的CPU开销来达到设计师所设计的表现力,则足以考验每一位UI开发人员的制作功底。
目前,我们在UWA测评报告中将统计意义上CPU开销最为耗时的几个函数进行展示,并将其详细的CPU占用和堆内存分配进行统计,从而让研发团队对UI系统的性能开销进行直接地掌握,同时结合项目截图对UI模块何时存在较大开销进行直观地定位。
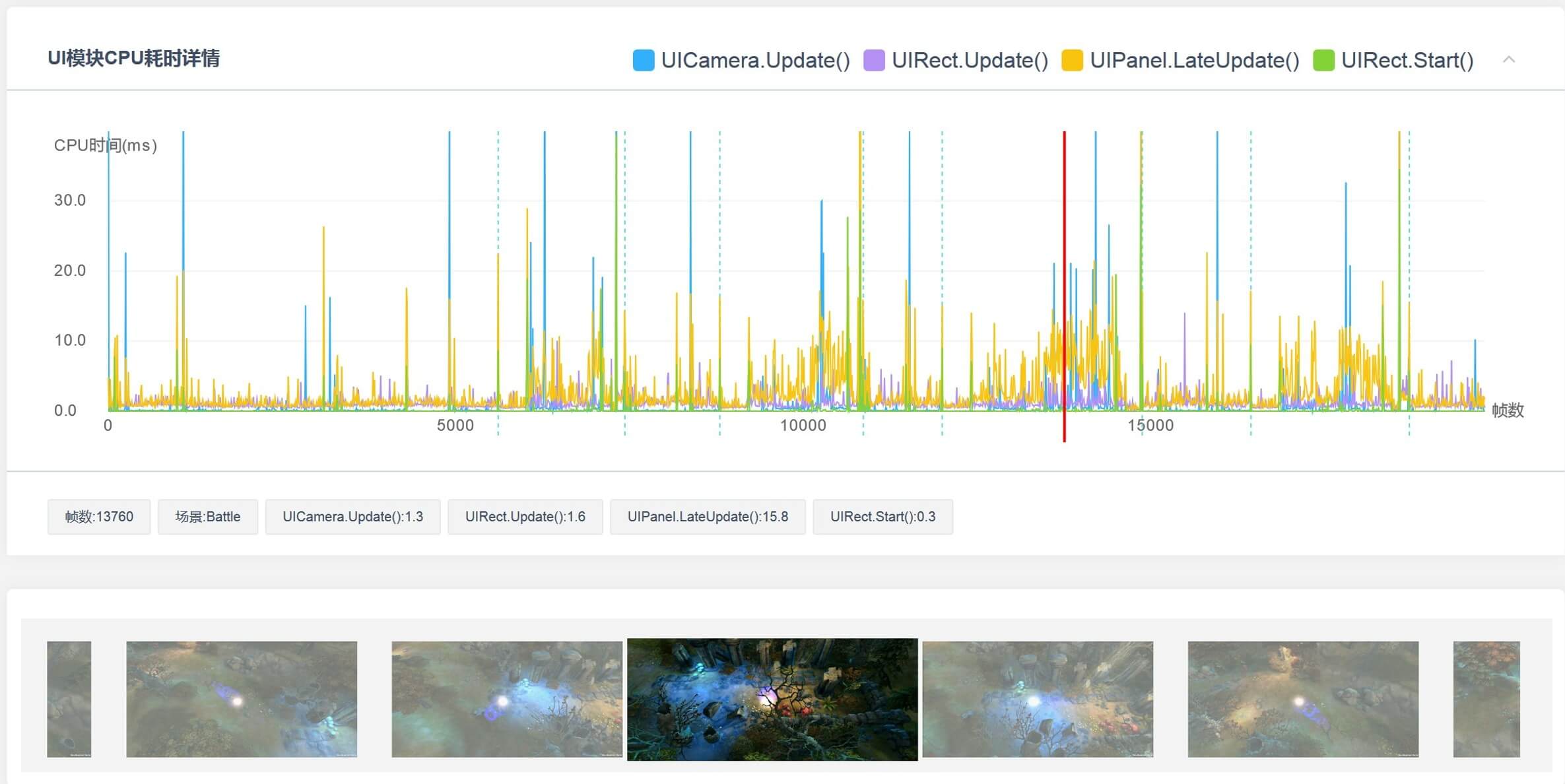
对于UIPanel.LateUpdate的优化,主要着眼于UIPanel的布局,其原则如下:
- 尽可能将动态UI元素和静态UI元素分离到不同的UIPanel中(UI的重建以UIPanel为单位),从而尽可能将因为变动的UI元素引起的重构控制在较小的范围内;
- 尽可能让动态UI元素按照同步性进行划分,即运动频率不同的UI元素尽可能分离放在不同的UIPanel中;
- 控制同一个UIPanel中动态UI元素的数量,数量越多,所创建的Mesh越大,从而使得重构的开销显著增加。比如,战斗过程中的HUD运动血条可能会出现较多,此时,建议研发团队将运动血条分离成不同的UIPanel,每组UIPanel下5~10个动态UI为宜。这种做法,其本质是从概率上尽可能降低单帧中UIPanel的重建开销。
另外,限于篇幅限制,我们在此仅介绍NGUI中重要性能问题,而对于UGUI系统以及UI系统自身的Draw Call问题,我们将在后续的UI模块技术专题中进行详细的讲解,敬请期待。
三、加载模块
加载模块同样也是任何游戏项目中所不可缺少的组成成分。与之前两个模块不同的是,加载模块的性能开销比较集中,主要出现于场景切换处,且CPU占用峰值均较高。
这里,我们先来说说场景切换时,其性能开销的主要体现形式。对于目前的Unity版本而言,场景切换时的主要性能开销主要体现在两个方面,前一场景的场景卸载和下一场景的场景加载。下面,我们就具体来说说这两个方面的性能瓶颈:
(1)场景卸载
对于Unity引擎而言,场景卸载一般是由引擎自动完成的,即当我们调用类似Application.LoadLevel的API时,引擎即会开始对上一场景进行处理,其性能开销主要被以下几个部分占据:
- Destroy
引擎在切换场景时会收集未标识成“DontDestoryOnLoad”的GameObject及其Component,然后进行Destroy。同时,代码中的OnDestory被触发执行,这里的性能开销主要取决于OnDestroy回调函数中的代码逻辑。
- Resources.UnloadUnusedAssets
一般情况下,场景切换过程中,该API会被调用两次,一次为引擎在切换场景时自动调用,另一次则为用户手动调用(一般出现在场景加载后,用户调用它来确保上一场景的资源被卸载干净)。在我们测评过的大量项目中,该API的CPU开销主要集中在500ms~3000ms之间。其耗时开销主要取决于场景中Asset和Object的数量,数量越多,则耗时越慢。
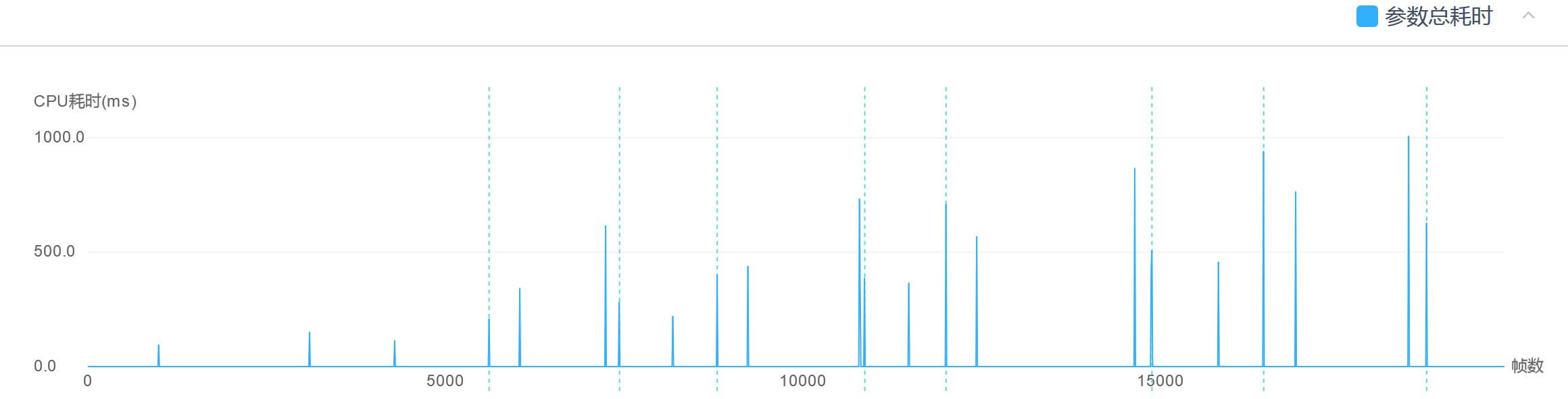
(2)场景加载
场景加载过程的性能开销又可细分成以下几个部分:
- 资源加载
资源加载几乎占据了整个加载过程的90%时间以上,其加载效率主要取决于资源的加载方式(Resource.Load或AssetBundle加载)、加载量(纹理、网格、材质等资源数据的大小)和资源格式(纹理格式、音频格式等)等等。不同的加载方式、不同的资源格式,其加载效率可谓千差万别,所以我们在UWA测评报告中,特别将每种资源的具体使用情况进行展示,以帮助用户可以立刻查找到问题资源并及时进行改正。
- Instantiate实例化
在场景加载过程中,往往伴随着大量的Instantiate实例化操作,比如UI界面实例化、角色/怪物实例化、场景建筑实例化等等。在Instantiate实例化时,引擎底层会查看其相关的资源是否已经被加载,如果没有,则会先加载其相关资源,再进行实例化,这其实是大家遇到的大多数“Instantiate耗时问题”的根本原因,这也是为什么我们在之前的AssetBundle文章中所提倡的资源依赖关系打包并进行预加载,从而来缓解Instantiate实例化时的压力(关于AssetBundle资源的加载,则是另一个很大的Story了,我们会在以后的AssetBundle加载技术专题中进行详细的讲解)。
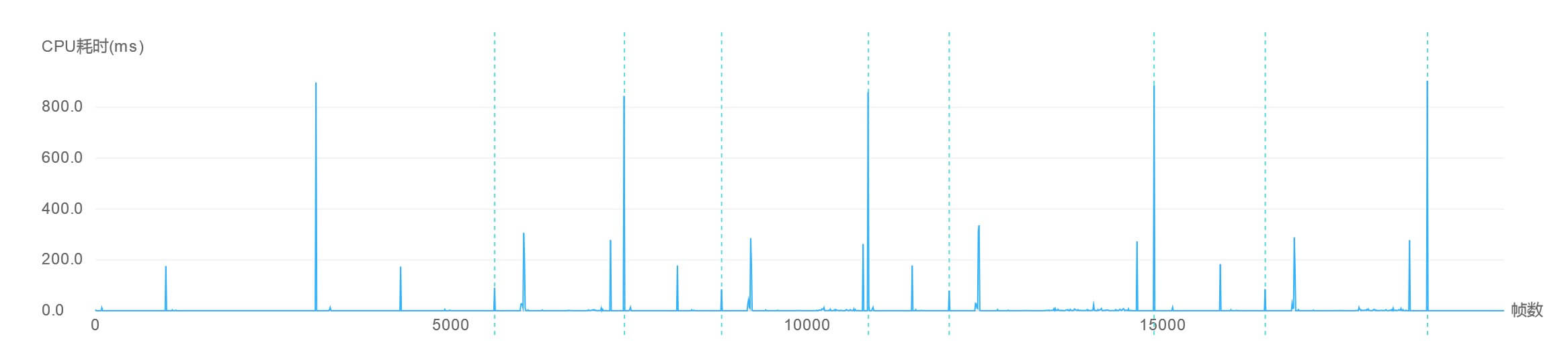
另一方面,Instantiate实例化的性能开销还体现在脚本代码的序列化上,如果脚本中需要序列化的信息很多,则Instantiate实例化时的时间亦会很长。最直接的例子就是NGUI,其代码中存在很多SerializedField标识,从而在实例化时带来了较多的代码序列化开销。因此,在大家为代码增加序列化信息时,这一点是需要大家时刻关注的。
以上是游戏项目中性能开销最大的三个模块,当然,游戏类型的不同、设计的不同,其他模块仍然会有较大的CPU占用。比如,ARPG游戏中的动画系统和物理系统,音乐休闲类游戏中的音频系统和粒子系统等。对此,我们会在后续的技术专题中进行详细的讲解,敬请期待。
四、代码效率
逻辑代码在一个较为复杂的游戏项目中往往占据较大的性能开销。这种情况在MOBA、ARPG、MMORPG等游戏类型中非常常见。

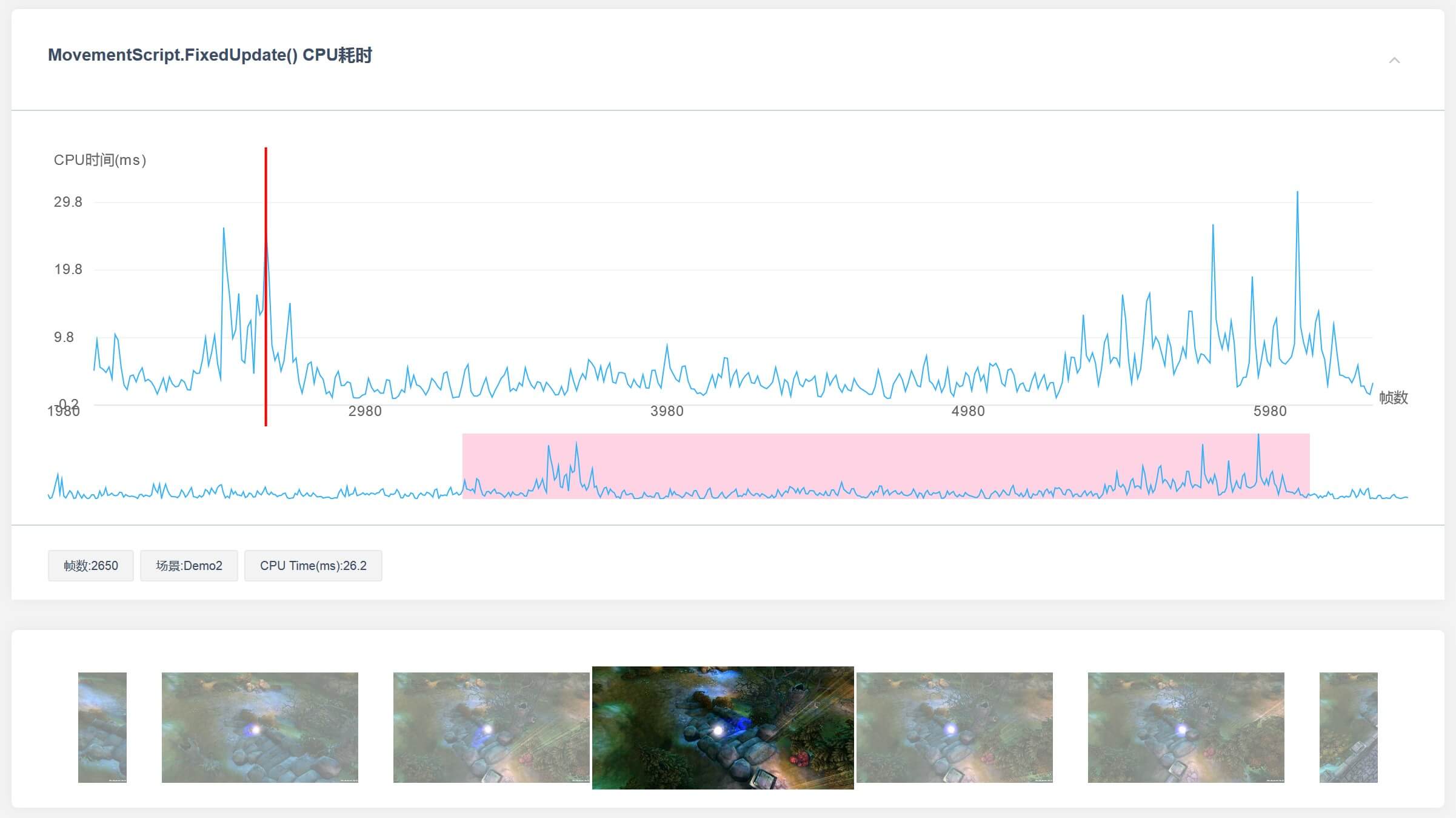
在项目优化过程中,我们经常会想知道,到底是哪些函数占据了大量的CPU开销。同时,绝大多数的项目中其性能开销都遵循着“二八原则”,即80%的性能开销都集中在20%的函数上。所以,我们在UWA测评报告中将项目中代码占用的CPU开销进行统计,不仅可以提供代码的总体累积CPU占用,还可以更近一步看到函数内部的性能分配,从而帮助大家更快地定位问题函数。
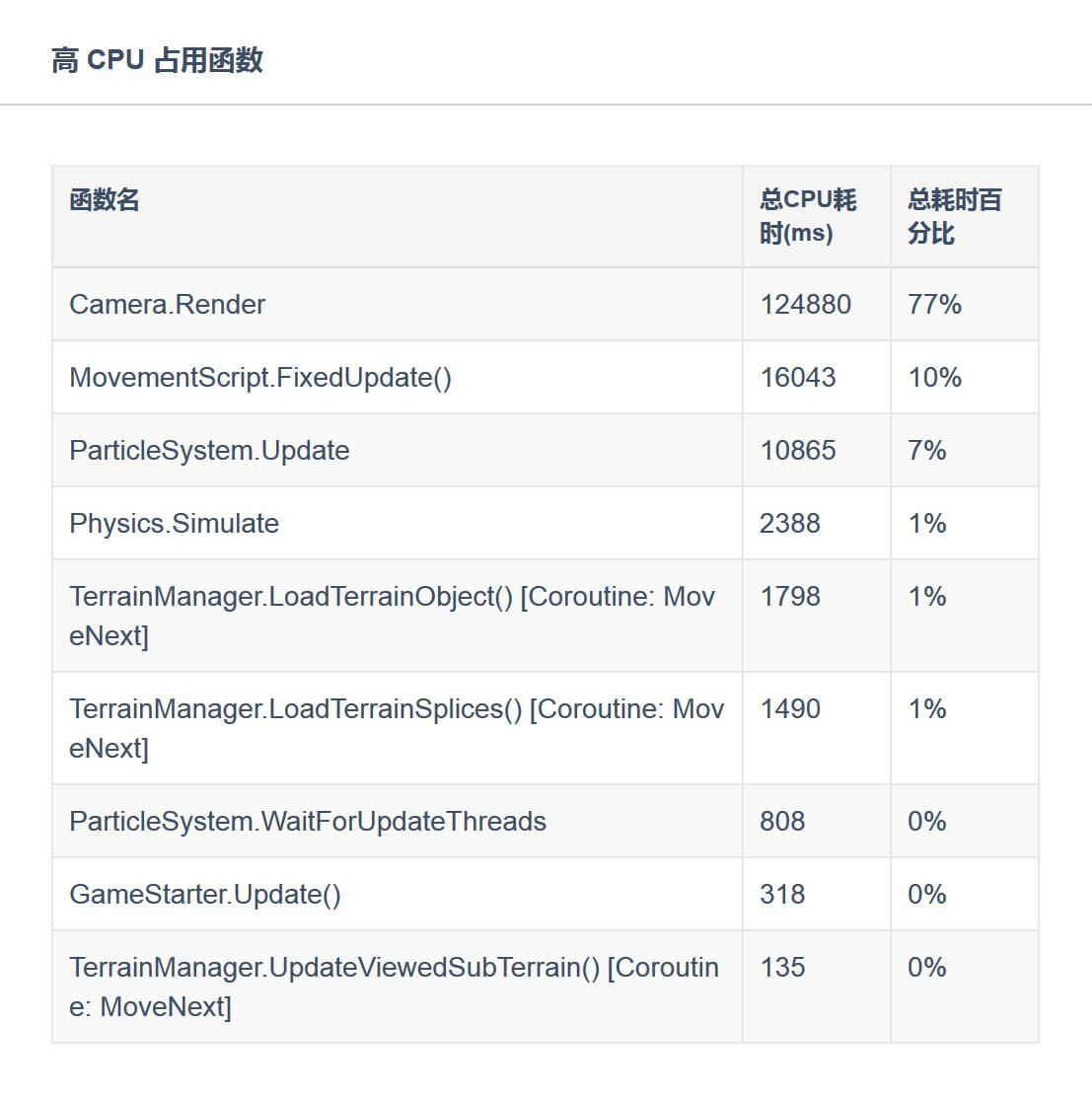
当然,我们还希望可以为大家提供更多的代码性能信息,比如函数任何一帧中更为详细的性能分配、更为准确的截图信息等等。这些都是我们目前正在努力研发的功能,并在后续版本中提供给大家进行使用。